Adding non-NULL value columns with values to a busy table – ONLINE
Adding a non-null column to a big table on a busy database can be tricky business. It might seem to be an easy task of altering table and adding a column ( an integer data type column – 4 bytes more or less, who cares) but it’s not. DBAs are always extra careful when perform those sorts of actions since it can cause serious implications to the db applications. For example, adding a non-null column to a busy table which contains 10M rows means that every row must be updated with a value. The table may be accessed by many different applications many times in a short period of time. These requests can be seriously blocked by the alter table/add a not null column/update column with a value, causing app timeouts, deadlocks and all sorts of headaches.
One of the common approaches is to add a NULL column and then to update the column values across all rows using the batch update scenario (update N number of rows per transaction) and then to alter column as non-null. This operation is usually performed “offline” or when the table is “quiet”.
Starting with SQL 2012+(Enterprise Edition) the operation is not “painful” any more. Adding column(s) to a busy table is now instantaneous and has less impact to the OLTP operations. In fact, the operation can be performed online.
This still requires taking into the consideration other factors that can impact the operation such as; data type of the new column, row length etc.
The task for today will be to add a new , non-null column of integer data type with the default value 46 to a busy table that has 1M rows 🙂
Test table
IF OBJECT_ID('dbo.addANonNullColOnline','U') IS NOT NULL
DROP TABLE dbo.addANonNullColOnline
GO
--create a test table
SELECT TOP 1000000 id = IDENTITY(INTEGER,1,1)
,val = CAST(c2.[name] +'AAAA' AS VARCHAR(4)) --fill all 4 bytes
COLLATE DATABASE_DEFAULT
INTO dbo.addANonNullColOnline
FROM sys.columns c1
CROSS JOIN sys.columns c2
CROSS JOIN sys.columns c3
GO
--set one value to NULL
UPDATE dbo.addANonNullColOnline
SET val = NULL
WHERE id = 2
id val ----------- ----- 1 bitp 2 NULL 3 colg 4 hbco 5 maxi 6 null 7 offs ... ... 10000000 runt
The table contains 1M rows. One row, id=2 has a NULL value for column “val”. The rest of the column values are taking the maximum available space of 4bytes.
NOTE: Varchar stores non-unicode characters e.g VARCHAR(4) =’AAAA’ takes 4bytes. (1 byte per non-unicode character).
The query below provides basic information about the table rows:
SELECT index_level
,page_count
,record_count
,min_record_size_in_bytes
,max_record_size_in_bytes
,avg_record_size_in_bytes
,SizeInMB = ROUND( ((record_count * avg_record_size_in_bytes) /1024.00 )/1024.00,0)
FROM sys.dm_db_index_physical_stats(db_id('test'),object_id('dbo.addANonNullColOnline','U'),null,null,'detailed')

The metadata information shows that the “shortest” row (id = 2) takes 11bytes of disk space, and the “longest” row(all other rows) takes 19bytes. The whole table(all rows) takes around 18MB of the disk space.
Before we add a new, not null column to the table, lets show how the rows are physically stored.
Rows physical storage
In this case, rows are stored using the FixedVar storage format. The name comes from the order in which Sql Server storage engine stores different data types – fixed data types(integer, decimal, char..) and then variable data types(nvarchar, varchar, varbinary..).The format has been used since Sql Server 7.0(Sphinx) released in 1998. ![]() .
.
FixedVar format internally adds a number of additional bytes to every row on page. The extra space per row is used to provide information about rows itself like (if the row has been deleted/ghost ,the number of columns, columns with NULL values, position of the variable columns if any, timestamp and pointer to the verison store if optimistic locking is enabled.. etc..).
For the fixed columns, storage engine will add:
6bytes + CEILING(TotalNoOfColumns / 8.00bytes)
..and for the variable part of the row
2bytes(if at least one of the varColumns has non-null value) + 2bytes * NoOfVariableNonNULLColumns.
In our example, the minimum row size(11bytes , row id=2) and the maximum row size( all other rows 19 bytes) will be..
--min_record_size_in_bytes
SELECT [FixedPart: 6 + CEILING(2/8.00)] = 6 + CEILING(2/8.00)
,[FixedColumnValue(INT) bytes] = 4
,'---'='---'
,[VariablePart: 0 + 2*0] = 0 +2* 0 --no non-null variableColumns
,[VariableColValue(VARCHAR(4)] = NULL
,TotalRowSize = 6 + CEILING(2/8.00) + 4 + 0
GO
--max_record_size_in_bytes
SELECT [FixedPart: 6 + CEILING(2/8.00)] = 6 + CEILING(2/8.00)
,[FixedColumnValue(INT) bytes] = 4
,'---'='---'
,[VariablePart: 2 + 2*1] = 2 +2* 1
,[VariableColValue(VARCHAR(4) bytes] = 4
,TotalRowSize = 6 + CEILING(2/8.00) + 4 + 4 + 4
GO
The image below shows the structure of a FixedVar row (Pro Sql Server Internals by Dimitri Korotkevitch)

Now, down to the bits and bytes, lets find the first data page(out of 2598) that is allocated to the table and try to reconcile the min and a max row. The undocumented internal column/fn %%Lockres%% gives us FileId:PageId:SlotId for the selected rows.
SELECT TOP(5) f.*
,%%lockres%% as [FileId:PageId:SlotId]
FROM dbo.addANonNullColOnline f
ORDER BY id
The query selects first few rows from the test table.
id val FileId:PageId:SlotId ----------- ---- -------------------------------- 1 bitp 1:16576:0 2 NULL 1:16576:1 3 colg 1:16576:2 4 hbco 1:16576:3 5 maxi 1:16576:4 (5 row(s) affected)
With the PageID of the page we want to examine, the next step is to allow sql server to redirect the page content output to the screen. To achieve this we can use DBCC(Database Console Command). The system change will affect only the current session.
--check the current state of the flag DBCC TRACESTATUS(3604) GO DBCC TRACEON(3604,-1) --sets up traceflag 3604 value to true on a session level GO --displays the first page DBCC PAGE (0,1,16576,3) --WITH TABLERESULTS GO
The page snapshot below shows the first page header(first 98bytes of the total page size – 8192bytes) and the first couple of rows. The relevant information for this exercise is highlighted.

The page is read from the disk and put into the buffer pool. The relevant information on the page:
- File No : Page number (1:16576)
- m_lsn = (525:62471:2) – Log Sequence Number.
- The position of the first row.
Slot(0) – the first row on the page
Offset 0x60 – the physical position from the beginning of the page (Hex 0x60 = 96bytes)
Length = 19* Happens to be the maximum record size. All rows exept row no 2 (id =2) are 19bytes. - The first row -hexadecimal(byte swapped values)
30000800 01000000 02000001 00130062 697470
03 – TagA 1 byte
00– TagB 1 byte
0008 – Fsize 2 bytes – location of the end of the last fixed datatype column.
8bytes = 1b(TagA) +1b(TagB) + 2bytes(Fsize itself) + 4b(INT column)
00000001 – The fixed data type column values. One int column with value 1.
0002 – Total number of columns (2bytes) =decimal 2
00 – NullBitmap 1byte = CEILING(TotalNoOfColumns / 8.00bytes) = CEILING(1/8.00bytes)
TOTAL Fixed part of the row: 1+1+2+4+2+1 = 11bytes
0001 – 2bytes – No. of variable type columns = decimal 1 (If all of the variable data type columns are NULL, this will be 0bytes.)
0013 – 2bytes – Every two bytes stores the location of the end of a variable,not NULL data type column. In this case there is only one variable column = decimal 19 – the var. column ends on 19th byte.
(2bytes * NoOfVariableNonNULLColumns)
62 697470 – 4 bytes – The actual variable column value ‘bitp’
SELECT CONVERT(VARBINARY(4), 'bitp')
Column 2 value -------------- 0x62697470 (1 row(s) affected)
TOTAL Variable part of the row: 2+2+4 = 8bytes
Total row1 size = 11bytes(Fixed part) + 8bytes(variable part) = 19bytes
- Column “id” value, first row
- Column “val” value, first row
- The position of the second row.
Slot(1) – second row on the page
Offset 0x73 – the physical position from the beginning of the page (Hex 0x73 = 115bytes). This is header(96bytes) + first row(19bytes)
Length = 11* Happens to be the minimum record size. All othere rows are 19bytes. - Second row -hexadecimal(byte swapped values)
10000800 02000000 020002
01 – TagA 1 byte
00– TagB 1 byte
0008 – Fsize 2 bytes – location of the end of the last fixed datatype column.
8bytes = 1b(TagA) +1b(TagB) + 2bytes(Fsize itself) + 4b(INT column)
00000002 – The fixed data type column values. One int column with value 2.
0002 – Total number of columns (2bytes) =decimal 2
02 – NullBitmap 1byte = CEILING(TotalNoOfColumns / 8.00bytes) = CEILING(1/8.00bytes) 02hex = 0010bin. This indicates that the second column (second bit is on) in the row contains NULL value.
TOTAL Fixed part of the row: 1+1+2+4+2+1 = 11bytes
Since the only variable column contains NULL value, the variable part does not take any space.
Total row2 size =11bytes(Fixed part) = 11bytes
-
- Column “id” value, second row
- Column “val” value, second row
- Slot 1 Column 2 Offset 0x0 Length 0 Length (physical) 0
This shows that the position of the column 2 in the row 2 is 0 and the physical length of the column is also 0. This means that the value is not physically stored on the page. The NULL value during the materialisation of the column value comes from theNullBitmap byte 02
Add a new column
Finally, we will add a column to our “hot” table. The column will be a non-null integer with the default value of 46.
ALTER TABLE dbo.addANonNullColOnline
ADD NewCol INT NOT NULL
CONSTRAINT DF_NewCol DEFAULT(46)
GO
SELECT *
FROM addANonNullColOnline
The action will “add” a new column and 1M 46-es in a few milliseconds. We can confirm that the new column with the values is real(materialised).
id val NewCol ----------- ----- ----------- 1 bitp 46 2 NULL 46 3 colg 46 4 hbco 46 5 maxi 46 6 null 46 7 offs 46 ... ... 10000000 runt 46
How it works
After adding a new, integer data type column, we expect to see increase in row size( by 4 bytes). We also expect that Sql Server storage engine somehow managed to add 1M 4byte integer values to the table in a fraction of second.
Let’s check rows metadata again.
SELECT index_level
,page_count
,record_count
,min_record_size_in_bytes
,max_record_size_in_bytes
,avg_record_size_in_bytes
,SizeInMB = ROUND( ((record_count * avg_record_size_in_bytes) /1024.00 )/1024.00,0)
FROM sys.dm_db_index_physical_stats(db_id('test'),object_id('dbo.addANonNullColOnline','U'),null,null,'detailed')
The query result shows that there were no changes in the row sizes.
So, what actually happened? Knowing that table rows are stored on data pages(RowStore – FixedVar storage format), we would expect increase in min and max row sizes. Using the formulas above…
min_record_size_in_bytes (row id=2) = 6 + CEILING(2/8.00) + 4 + 4 + 0 + 2*0 = 6 + 1 + 8 = 15
max_record_size_in_bytes = 6 + CEILING(2/8.00) + 4 + 4 + 2 + 2*1 + 4 = 6 + 1 + 8 + 4 + 4 = 23
The formulas are correct but the result is not 🙂
If we check the first page again, we’ll notice that
– m_lsn (log sequential number) has not changed
– The new column (NewCol) is not stored on the page (offset from the beginning of the rows is 0bytes)

The unchanged m_lsn shows us that there were no changes on the page.
More about m_lsn
m_lsn – represents the last Log Sequential Number related to the last transaction that changed the page. The set of log records which describe the changes(old and new version of the data, transaction, affected row etc.) starts with the same lsn. The log information allow SQL Server to recover databases to transnationally consistent state in case of system crash or any unexpected shut down.
SQL Server uses WAL(Write-Ahead-Log) model which guarantees that no data modifications will be written to disk before the associated log record is written to the disk.
Example: A transaction T1 updates a few columns in a row. The high level sequence of events will be:
- A Data access operator requests from the buffer pool manager(BPM) data page that contains rows to be updated . BPM checks if the page already exists in the buffer pool. If not, BPM requests I/O operations to retrieve the page from the disk.
- The update operation(transaction T1) updates relevant row on the page in the buffer pool. The page header information m_lsn is updated. The operation creates a set of new log records(starting with the the same m_lsn) that describes changes made to the page. The log records are created in the log buffer.
- Transaction T1 commits the changes. Log buffer manager flushes the content of log buffer(~64kb) to the disk(log file).
- Client application receives confirmation that the transaction T1 has been successfully committed.
New column metadata
After creating a new, non-null column, instead of updating all 1M rows with some value, Sql Server 2012+(Enterprise Ed) stores the information as metadata.
SELECT TableName = object_name(p.object_id)
,ColumnType = type_name(pc.system_type_id)
,pc.max_length
,pc.[precision]
,pc.scale
,pc.is_nullable
,has_default
,default_value
FROM sys.system_internals_partitions p
INNER JOIN sys.system_internals_partition_columns pc
ON p.partition_id = pc.partition_id
WHERE p.object_id = object_id('dbo.addANonNullColOnline');

The two metadata columns hold the information about the added column. This is where 46 is materialised from, not from the page, but from the metadata.
This new behavior occurs automatically and does not impact the system.
default_value / has_default
The defaut_value / has_default columns which belongs to sys.system_internals_partition_columns system view are not related to DF_NewCol Default Constraint defined during the table alteration.
The metadata that describes the default constraints can be found using the query below
SELECT parentTable = object_name(dc.parent_object_id)
,dc.name
,dc.type_desc
,dc.[definition]
FROM sys.default_constraints dc
WHERE dc.name = 'DF_NewCol'
If we drop the constraint, has_default/ default_value will stay intact.
row UPDATE
An interesting thing will happen when we update a row. Let’s update row id=2 and replace the NULL value with something.
UPDATE dbo.addANonNullColOnline
SET val = 'Hi 5'
WHERE id = 2;
id val NewCol ----------- ----- ----------- 1 bitp 46 2 Hi 5 46 3 colg 46 4 hbco 46 5 maxi 46 6 null 46 7 offs 46 ... ... 10000000 runt 46
…and now the max,min rowsizes are changed.

Whenever we update one or more values in a row, the default value (NewCol = 46) will be written on the data page. The rows that are not updated will still materialise value 46 from the metadata.
If you inspect the first page, you’ll find that the page has a new m_lsn and that all the column values of the row are written on the page
Before the change, the shortest row was row2 (id=2), size = 11b. Now, after the update, the row2 size increased to 23b. The NewColumn default value (46) now became a physical part of the row.
Using the formulas mentioned before, the new min/max row sizes are:
max_record_size_in_bytes (row id=2) = 6 + CEILING(2/8.00) + 4 + 4 + 2 + 2*1 + 4 = {6 + 1 + 8 } + {4 + 4 }= 23
**4bytes for the NewCol value of 64 and 4bytes for ‘Hi 5’ value that replaced NULL value
min_record_size_in_bytes (all rows expect row id=2) = 6 + CEILING(2/8.00) + 4 + 2 + 2*1 + 4 = 6 + 1 + 4 + 4 + 4 = 19
Table row source(s)
The figure below shows that the test table materialises column values from two different sources – data pages and metadata.

We see that only the updated row (id=2) has all the columns physically stored on the data page.
E.g row 1 is physically stored in Slot 0, but the new column is not part of the row
Slot 0 Column 3 Offset 0x00 Length 4 Length (physical) 0
NewCol = 46
During the production life, all the table rows may be gradually updated. The has_default / default_value values(1 and 46 respectively) metadata remain but will not be in use.
Metadata will be removed if we REBUILD the table
ALTER TABLE dbo.addANonNullColOnline
REBUILD;
Restrictions
There are a few data types that cannot be added online.
- Varchar(max)
- NVarchar(max)
- Varbinary(max)
- XML
- hierarchy_id
- geometry
- geography
Default expressions that are not runtime constant (expressions that require a different value for each row) cannot be added online. e.g NewId(),NewSequentialId() ..
Row-overflow row storage format is not supported. New columns must not increase the maximum row size over 8060 bytes limit.
Conclusion
Starting from Sql Server 2012 (Enterprise Ed) it is possible to add, ONLINE, non null columns with values to a busy table. Sql Server storage engine uses metadata to store the default values for the added columns. When requested, the table columns are materialised from data pages and metadata. There are restrictions on the data types that may be used. e.g columns with BLOB datatypes cannot be added online.. etc. Only the runtime constant expressions can be used as a default constraints.
Thank you for reading
Dean Mincic



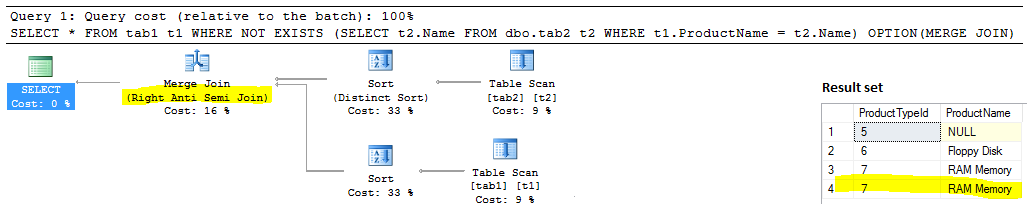





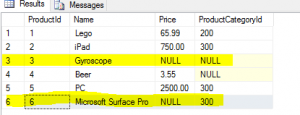 UNIQUE Constraint and Set operators
UNIQUE Constraint and Set operators



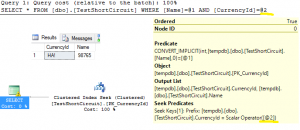
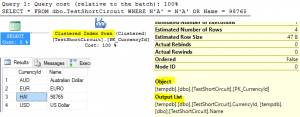 Figure 2: Disjunctive predicates, query simplification and SC
Figure 2: Disjunctive predicates, query simplification and SC