Summary
In SQL Server, a GUID/UUID – Globally Unique Identifier/Universally Unique Identifier is a 16byte binary value represented as a UNIQUIEIDENTIFIER data type. The idea is to generate and store values that are unique across different database servers and networks. There are several ways to create these values e.g using client code i.e System.Guid.NewGuid() method in .NET, NEWID() / NEWSEQUENTIALID() functions in SQL Server etc.
There are many SQL Server databases designed to use GUID as a surrogate, primary key, and/or clustered index key. This is to enforce entity(table) integrity and/or logical order of the rows. These, somehow common decisions in the industry may cause design and performance issues. This post explores several such scenarios and the possible reasoning behind them.
GUID structure
A GUID is a 16byte(128bit) unsigned integer. It’s a lot of combinations of digits, 2128 or 1038 to be precise. The available space is logically divided into five segments separated by hyphens. This is how the 16byte space is represented to us.
In SQL Server, in addition to the uniqueidentifier, we can also use binary, Unicode, and non-Unicode datatypes (variable or fixed length) to store GUID values – more on that in the following section.
Let’s store a big, positive numeric value into a UNIQUEIDENTIFIER and in a BINARY data type of the same size(16bytes), and see what happens.
DECLARE @BigNumeric DECIMAL(28,0) = 1234567898765321234567898765;
/*
For the demonstration I used a positive integer that requires more than 8bytes of space
*/
DECLARE @binary16 BINARY(16)
,@guid UNIQUEIDENTIFIER
SET @binary16 = @BigNumeric
SET @guid = @binary16 --implicit conversion from a numeric to uniqueidentifier is not permitted
SELECT [decimal] = @BigNumeric
,[binary(16)] = @binary16
, [GUID] = @guid;
--to convert back to numeric
/*
SELECT CONVERT(DECIMAL(28,0), @binary16) --bin -> numeric
SELECT CONVERT(DECIMAL(28,0),CONVERT(BINARY(16), @guid)) --guid -> bin -> numeric
*/
GO

Figure 1, A big numeric value stored as binary and uniqueidentifier
We can see that the number stored as UNIQUEIDENTIFIER (16byte binary) data type is represented in hexadecimal form and formatted in an 8 – 4 – 4 – 4 – 12 pattern. That is exactly 16bytes (4b-2b-2b-2b-6b) with each byte represented as a pair* of characters i.e the far right byte holds hexadecimal number 03. So, 16bytes are stored and 32+4 characters are displayed(including the hyphens).
*NOTE: In SSMS, binary values are represented as hexadecimal numbers with the 0x prefix. In fact, many computer languages allow programmers to indicate that a value within a program is a hexadecimal number. In the representation above, each byte is represented as a pair of characters(hex numbers) i.e from Figure1, FD03 – two far-right bytes, FD00 -> 64,768(decimal) , 0003 -> 3(decimal) and together they give 64,771(decimal) – More on hex to dec conversion can be found here.
Interestingly, UNIQUEIDENTIFIER does not store information exactly the same as a raw, BINARY data type.
Figure1 shows that UNIQUEIDENTIFIER stores the first 16 hexadecimal digits(the first 8 rightmost bytes) exactly the same as BINARY. The remaining three segments store bytes in reversed order.
The first 8bytes(the last two segments) are an 8-element byte array. In general, array elements are stored in index order and that is why they match the row binary storage pattern. The remaining three segments contain re-shuffled byte ordering and that is a feature of the UNIQUEIDENTIFIER data type. On top of that, the Microsoft OS byte encoding (Endianness) pattern depends on the underlying CPU architecture i.e Intel processors implement the little-endian encoding. This deviates from the RFC standard, which imposes the use of the Big Endian byte ordering.
To make things more confusing, let’s compare BINARY and UNIQUEIDENTIFIER byte footprints on the data page. For this experiment, I’ll store the values from Figure 1 in a table. Execute this code and observe the results.
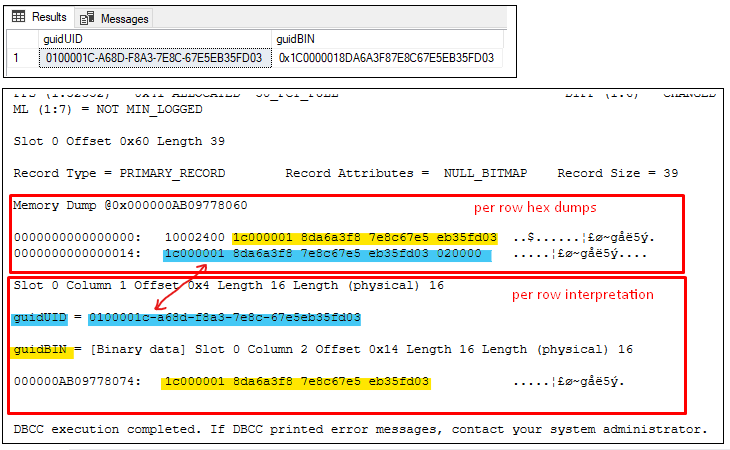
Figure 2, UNIQUEIDENTIFIER values on a data page
It seems that the UNIQUEIDENTIFIER value is stored exactly the same as the BINARY value without byte rearrangements. However, the same value is presented with the reshuffled bytes.
RFC4122 is a standard that defines how to structure UUID. This is a set of rules on how to generate values, represented in the four segments (presented as a five-segment string), which together form a globally unique number.
The functions like System.Guid.NewGuid() or NEWID() are based on these rules.
Ways to store GUIDs in SQL Server
UNIQUEIDENTIFIER is a data type designed to store GUID values. In practice, however, programmers sometimes choose binary, Unicode, or non-Unicode data types to store those values. The string data types require significantly more space. There are also concerns about sorting and casting.
- BINARY(16) – 16bytes
- CHAR(36) – 36bytes
- NCHAR(72) – 72bytes
The script below shows different storage space requirements for the same GUID value:
DECLARE @guid UNIQUEIDENTIFIER = '18eb083c-39dd-4859-ad7f-0392077c32cb'
SELECT [GUID] = @guid
,[uniqueidentifier(bytes)] = DATALENGTH(@guid)
,[binary(bytes)] = DATALENGTH(CONVERT(VARBINARY(100),@guid))
,[non-unicode(bytes)] = DATALENGTH(CONVERT(VARCHAR(100),@guid))
,[unicode(bytes)] = DATALENGTH(CONVERT(NVARCHAR(100),@guid));
GO

Figure 3, space required to store a GUID value
Figure 3 shows that if we decide to use e.g Unicode data type to store GUID we’ll need 4.5x more space than if we use UNIQUEIDENTIFIER or BINARY data type.
BINARY data type conversions
According to SQL Server Data Type Conversion Chart (download here), UNIQUEIDENTIFIER value can be implicitly converted to a string and binary datatypes.
In the next experiment, client code generates a GUID value and passes it to a stored procedure as a parameter of type string. The stored proc then inserts the guid value into a table as string, binary, and the uniqueidentifier.
The Python code can be found here and the TSQL script can be found here.
...python code segment..
ui = uuid.uuid4() #create a guid value
sql = "EXECUTE dbo.TestGUIDinsert @guid = ?" #define tsql command and params
params = ui
#execute stored proc
cursor.execute(sql,params) ##RPC call - parameterised batch request
...
After running the code above and SELECT * FROM dbo.TestGUIDstore;
 Figure 4, string GUID to BINARY conversion
Figure 4, string GUID to BINARY conversion
The test shows a peculiar value in the uid_bin16 column. This is not the expected GUID value stored as BINARY(16). So what is it?
Storing GUID values using explicit conversion from string to BINARY(16) results in the loss of the GUID values.
NOTE: Just a couple observations, not directly related to this post. The Python script above connects to the DB using pyodbc library (odbc provider). All versions of the provider, by default, have the autocommit connection string property set to False. This sets the IMPLICIT_TRANSACTIONS to ON. Try to exclude the property param from the conn. str. and see what happens. The second interesting thing is the way the “execute” method executes the query(RPC call, parameterized batch request). More on the two topics can be found here(Data Providers and User Options) and here(Client Requests and SQL Events in SQL Server)
From the previous experiment:
--Default: Style =0
SELECT CONVERT(BINARY(16),'D9DD9BA5-535C-46C3-888E-5961388C089E',0)
--Result: 0x44394444394241352D353335432D3436
…and if we try to convert the binary value back to GUID i.e this time to UNIQUEIDENTIFIER
SELECT CONVERT(UNIQUEIDENTIFIER,0x44394444394241352D353335432D3436)
--Ressult: 44443944-4239-3541-2D35-3335432D3436
The retrieved GUID is totally different than the one originally stored in the table.
The reason for this behavior lies in the explicit conversion from string to BINARY(16).
What Python program sent, ‘D9DD9BA5-535C-46C3-888E-5961388C089E’, is a string representation of a GUID. The format is recognizable by UNIQUEIDENTIFIER data type. However, for BINARY data type, this is just a set of ASCII characters, not a hex string – a hexadecimal value represented as a string. Moreover, the ASCII set of characters requires 36bytes to be stored as a hex string.
Just to illustrate the point(and because I found it interesting 🙂 ), the following script takes out each char from the GUID script, gets its ASCII code, converts the code into a hexadecimal value, and put it back into its position. i.e char ‘D’ is ASCII 68 and hex 44.
DECLARE @guidString CHAR(36) = 'D9DD9BA5-535C-46C3-888E-5961388C089E';
DECLARE @result VARCHAR(72)=''; --stores the final result
;WITH N1(n) AS --generate 6 rows
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),numbers(n1) AS --use cartasian product (6x6) to get enough rows to match the GUIDs 36 chars
(
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) --construct a sequence of numbers 1-36
FROM N1,N1 a
),getHexAscii AS
(
SELECT n1
,chars = SUBSTRING(@guidString,n1 ,1) --use seq. no. to navigate to the chars to be "extracted"
,[ascii] = ASCII(SUBSTRING(@guidString,n1 ,1)) --ascii code of the "extracted" char
,hexAscii = FORMAT(ASCII(SUBSTRING(@guidString,n1 ,1)),'X') --the ascii code formated as hex
FROM numbers
)
--consolidate the chars back to a hexstring
SELECT @result += getHexAscii.hexAscii
FROM getHexAscii
ORDER BY n1 ASC;
SELECT [GUID_hexString(72chars)] = @result
Now we can compare the binary value stored in the uid_bin16 column with the output from the script above:
0x44394444394241352D353335432D3436 (stored in the table)
44394444394241352D353335432D343643332D383838452D353936313338384330383945 (script)
Not only that the GUID is not stored correctly but, now we can see that half of the input string got truncated (it simply needs more space than 16bytes, as mentioned above).
If you still want to store GUIDs as a BINARY data type, one of the techniques is to remove hyphens and then convert the string to BINARY(16).
Note: un-comment –,uid_bin16 = CONVERT(BINARY(16),REPLACE(@guid ,’-‘,”),2) from the table definition code and run the Python script again. Inspect the stored values.
The following script demonstrates the same conversion approach.
DECLARE @guidString CHAR(36) = 'D9DD9BA5-535C-46C3-888E-5961388C089E';
DECLARE @guidBinary BINARY(16)
--Style 2
SELECT @guidBinary = CONVERT(BINARY(16),REPLACE(@guidString ,'-',''),2)
SELECT @guidBinary --Result: 0xD9DD9BA5535C46C3888E5961388C089E
The third parameter – Style, in this context, defines how the CONVERT function treats the input string. More information can be found here. In this case, Style = 2, instructs the function to treat the input string as a hex string with no 0x suffix. This is why we get the correct conversion.
Keep in mind that if you need to pull the binary information from DB and pass it to the client as GUIDs, the following conversion to UNIQUEIDENTIFIER will result in a similar but different GUID, as explained before.
DECLARE @guidString CHAR(36) = 'D9DD9BA5-535C-46C3-888E-5961388C089E';
DECLARE @guidBinary BINARY(16)
SELECT @guidBinary = CONVERT(BINARY(16),REPLACE(@guidString ,'-',''),2)
SELECT @guidBinary --Result: 0xD9DD9BA5535C46C3888E5961388C089E
--and convert to GUID
SELECT CONVERT(UNIQUEIDENTIFIER,@guidBinary)
/*
BINARY: 0xD9DD9BA5 535C 46C3 888E 5961388C089E
UNIQUEIDENTIFIER: A59BDDD9-5C53-C346-888E-5961388C089E
*/
Of course, you can always “STUFF” a few hyphens into the string representation of the BINARY to get a GUID string shape.
DECLARE @guidString CHAR(36) = 'D9DD9BA5-535C-46C3-888E-5961388C089E';
DECLARE @guidBinary BINARY(16)
SELECT @guidBinary = CONVERT(BINARY(16),REPLACE(@guidString ,'-',''),2)
SELECT @guidBinary --Result: 0xD9DD9BA5535C46C3888E5961388C089E
--and back to string (Style 2 (string representation without the leading 0x )
SET @guidString = CONVERT(VARCHAR(36),@guidBinary,2)
SET @guidString = STUFF(STUFF(STUFF(STUFF(@guidString,9,0,'-'),14,0,'-'),19,0,'-'),24,0,'-')
SELECT @guidString
--Result: D9DD9BA5-535C-46C3-888E-5961388C089E
The safest way to store a GUID as BINARY and to be able to retrieve the binary value, unchanged, as a UNIQUEIDENTIFIER is to first convert the input string to UNIQUEIDENTIFIER and then to BINARY(16) before storing it in DB. To retrieve GUID we just need to convert the BINARY(16) back to UNIQUEIDENTIFIER and the GUID will be unchanged.
Uncomment –,uid_bin16 = CONVERT(UNIQUEIDENTIFIER,@guid) in the code and repeat the test above. This time, the conversion back to the GUID is correct.
DECLARE @guidString CHAR(36) = 'D9DD9BA5-535C-46C3-888E-5961388C089E';
DECLARE @guid_bin16 BINARY(16)
--convert to binary (and store in db)
SET @guid_bin16 = CONVERT(BINARY(16),CONVERT(UNIQUEIDENTIFIER,@guidString))
SELECT [BINARY] = @guidString;
--retrieve the bin value from db, convert back to GUID and sent to client
SELECT [GUID] = CONVERT(UNIQUEIDENTIFIER,@guid_bin16)
Finally, it’s worth familiarising with the nuances when comparing and sorting guids/uniqueidentifiers using i.e System.Guid.CompareTo() vs SqlTypes.SqlGuid.CompareTo() methods. This is well explained here.
How to generate GUID in SQL Server
In SQL Server 7 Microsoft expanded replication services capabilities with the Merge replication. Replication in general provides loosely consistent data that adds more flexibility around network availability. This is opposed to distributed transactions which use the two-phase commit protocol that guarantees data consistency but potentially keeps the system locked for a long time i.e case of failed and/or in-doubt transactions. Merge replication allows both, publisher and subscriber(s) to independently modify published articles i.e tables. The system synchronizes the changes between the participants. To uniquely and globally identify rows across the published articles, Microsoft implemented* a new datatype – UNIQUEIDENTIFIER along with a new column property – ROWGUID and a new function for generating random guids – NEWID().
Currently, SQL Server offers two system functions for generating GUIDs
- NEWID()
- NEWSEQUENTIALID() -available since SQL Server 2005
Both functions are based on Windows functions, UuidCreate() and UuidCreateSequential() respectively.
*NOTE: Merge replication is not the only reason why Microsoft implemented UNIQUEIDENTIFIER and the support for GUIDs. The ability to manage globally unique values has become an important way of identifying data, objects, software applications, and applets in distributed systems (based on [Inside SQL Server 7.0, Microsoft Press,1999])
NEWID()
NEWID() is a system function that generates a random, globally unique GUID value of type UNIQUEIDENTIFIER. It’s based on UuidCreate() Windows OS function. NEWID() is compliant with the RFC4122 standard.
NEWID() is not a foldable function therefore it’s executed separately for each inserted row. This is opposed to the Runtime constant scalar functions i.e GETDATE(), GETSYSDATE(), RAND(), the functions that are executed only once per query.
NOTE: The runtime constant scalar functions are evaluated only once, early in the query execution. The results are cached and used for all resulting rows.. This process is known as Constant Folding.
The following script demonstrates how the function works and how it’s different to a foldable function.
DROP TABLE IF EXISTS #testNEWID;
GO
CREATE TABLE #testNEWID(GuidId UNIQUEIDENTIFIER ROWGUIDCOL --column property
DEFAULT NEWID()
,DateCreated DATETIME2
DEFAULT SYSDATETIME()
)
GO
--set based insert (sysdatetime folded - same value for all rows
--GuidId is different for each row)
INSERT INTO #testNEWID (GuidId,DateCreated)
SELECT TOP (5) guidId = NEWID()
,DateCreated = SYSDATETIME()
FROM sys.columns;
GO
SELECT * FROM #testNEWID
GO
--reset test
TRUNCATE TABLE #testNEWID
GO
--separate batch insert (dateCreated & GuidId different for each row)
INSERT INTO #testNEWID
DEFAULT VALUES;
GO 10
SELECT * FROM #testNEWID
GO

Figure 5, NEWID() , not foldable function
ROWGUIDCOL – is a column property( or a designator for a GUID column) similar to $IDENTITY. It is possible to have multiple UNIQUEIDENTIFIER columns per table, but only one can have the ROWGUIDCOL property. The designator provides a generic way for the client code to retrieve the GUID column, usually with unique values, from a table.
--get the last generated GUID
SELECT ROWGUIDCOL
FROM #testNEWID
WHERE DateCreateD = (SELECT MAX(DateCreated)
FROM #testNEWID)
NEWSEQUENTIALID()
NEWSEQUENTIALID() is a system function that creates a globally unique GUID that is greater than any GUID previously generated by this function on a particular computer and on a particular SQL Server instance on that computer. The output of the function is of type UNIQUEIDENTIFIER. NEWSEQUENTIALID() is based on Windows UuidCreateSequential() system function.
There are a few interesting quirks and features of this function.
- NEWSEQUENTIALID() system function cannot be invoked independently i.e SELECT NEWSEQUENTIALID(); It can only be used as a default constraint of a column in a table and the column must be of a UNIQUEINDENTIFIER data type. Also, it is not possible to combine this function with other operators to form a complex scalar expression.
CREATE TABLE #t(seqGuid UNIQUEIDENTIFIER
DEFAULT NEWSEQUENTIALID()
);
INSERT INTO #t
DEFAULT_VALUES;
GO 2
- All GUID values generated by NEWSEQUENTIALID() on the same computer are ever-increasing. From the SQL Server perspective, this means that all sequential guids generated across all instances, databases, and tables on the same server, are ever-increasing. The “shared counter” is due to the fact that the function is based on an OS function.
Also, the ever-increasing sequence continues after the OS restart. To demonstrate the point run this code
.
Figure 6, NEWSEQUENTIALID() – shared counter
- NEWSEQUENTIALID() is not guaranteed to be globally unique if initiated on a system with no network card. There is a possibility that another computer without an ethernet address generates the identical GUID. This is based on the underlying UuidCreateSequential() windows function behavior.
- NEWSEQUENTIALID() is not compliant with the RFC4122 standard
- The sequence of ever-increasing GUIDs will be interrupted after the OS system restart. The new sequence may start from a higher range – Figure 6, or it can start from a lower range. This is something that we cannot control.
- UuidCreateSequential() outputs sequential guids with different byte order than NEWSEQUENTIALID(). The reason is that the function outputs UNIQUEIDENTIFIER data type that, as it was mentioned before, re-shuffles certain bytes – see Figure 1. This may create problems with sorting in situations when the client code generates sequential guids and stores it in the database as UNIQUEIDENTIFIER(s). This article explains how to avoid this problem.
- Sequential guids generated, and re-shuffled as explained above, by the application that runs on the same server as the DB server will be in the same sort order as the sequential guids generated by newsequentialid() across all SQL Server instances on that server.
GUID & DB Design
Relational database systems such as SQL Server have a strong foundation in mathematics and in relational theory – hence the R in RDBMS, but they also have their own principles. For example, a Set is an unordered collection of unique, no-duplicated items. In relational theory, a relation is defined as a set of n-tuples. A tuple in mathematics is a finite sequence of elements. It has an order and allows duplicates. It was later decided that it would be more convenient, from the computer programming perspective, to use attribute names instead of ordering. The concept has changed but the name “tuple” remained. Back to RDBMS, a table is a visual representation of a relation and a row is similar to the concept of a tuple. These concepts are similar but not the same. E.g A table may contain duplicate values whereas a relation cannot have two identical tuples etc.
The consistency of an RDBMS is enforced by constraints that are declared as part of the DB schema e.g Primary Key constraint enforces the consistency of an entity. A tuple must have a minimal set of attributes that makes it unique within a relation. A row in a table does not need to be unique, and this is where, in my opinion, the big debate about natural keys vs surrogate keys begins.
We are designing databases with performances in mind. This includes deviations from the rigid rules of database design. The more we know about the internals of the RDBMS we use, the more we try to get the most out of it by adjusting our design and queries to it. Paradoxically, the declarative nature of SQL language teaches us to give instructions on what to do not how to do it. I guess, the truth is always somewhere in between :).
The above may explain the use of IDENTITY columns and primary keys that follow clustered index key guidelines: static, unique, narrow, and ever-increasing.
It is a common practice among developers to use GUIDs values as primary keys and/or clustered index keys. This choice ticks only one box from the PK/index key properties mentioned above – it’s unique and possibly static. Pretty much everything else is not ideal – GUID is not narrow(16bytes), not ever-increasing( unless generated by UuidCreateSequential()/NEWSEQUENTIALID() on the same PC). From a database design point of view, GUIDs are generally not good( they are meaningless, not intuitive surrogate keys) nor from the DB performances perspective(they cause fragmentation, unnecessary disk space consumption, possible query regression, etc). So why they are so “popular”?
GUID as Primary Key
The idea is to create a unique value e.g a new productId, on one of the application layers without performing a round-trip to the database in order to ask for a new Id. So, the generated GUID value becomes a PK value for the new product in e.g Products table. The PK may be implemented as a unique non-clustered index. The index is likely to be highly fragmented since the generated GUIDs are completely random. Also, keep in mind that the PK is highly likely to be a part of one or more referential integrity constraints(Foreign Keys) in tables like e.g ProductInventory, ProductListPriceHistory, etc. Moreover, the Foreign keys may be, at the same time, part of the composite PKs on the foreign tables – Figure 7. This design may have a negative effect on many tables and the database performance in general.
An alternative approach may be to define GUID column as an Alternate Key* enforced by a unique NCI and to use INT or BIGINT along with the IDENTITY property or a Sequencer as a surrogate PK. The key can be enforced by the unique clustered index. This way we can avoid excessive fragmentation and enforce referential integrity in a more optimal way – Figure 7,rowguid column.

Figure 7, GUID column as an Alternate Key – Adventure Works
*Alternate Key represents column(s) that uniquely identify rows in a table. A table can have more than one column or combinations of columns that can uniquely identify every row in that table. Only one choice can be set as the PK. All other options are called Alternate Keys.
GUID values can be created by SQL Server during the INSERT operations. E.g Client code constructs a new product (product name, description, weight, color, etc..) and INSERTs the information(a new row) into the Products table. The NEWID() fn automatically creates and assigns a GUID value to the new row through a DEFAULT constraint on e.g ProductId column. Client code can also generate and supply GUID for the new product. The two methods can be mixed since the generated GUIDs are globally unique.
What I often see in different production environments is that the GUID values are used as PK values even if there is no need for the globally unique values.
Very few of them had better security in mind i.e It is safer to expose a GUID than a numeric value when querying DB through a public API. The exposed numeric value in the URL may potentially be used to harm the system. E.g http://myApp/productid/88765 can suggest that there is productId =88764 etc., but with a GUID value, these guesses will not be possible – Figure 7, data access point.
In most DB designs, at least in the ones I’ve had an opportunity to work on, GUIDs are used only because it was convenient from the application code design perspective.
When the application and the database become larger and more complex, these early decisions can cause performance problems. Usually, these problems are solved by, so-called quick fixes/wins. As the rule of thumb, the first “victim” of those “wins” is always data integrity e.g adding NOLOCK table hints everywhere, removing referential integrity(FK), replacing INNER JOINS with LEFT JOINS, etc. This inevitably leads to a new set of bugs that are not easy to detect and fix. This last paragraph may be too much, but this is what I am seeing in the industry.
Use GUIDs with caution and with the cost-benefit in mind 🙂
GUID as PK and the Clustered index key
Sometimes developers decide to use GUID values as a PK enforced by the clustered index. This means that the primary key column is at the same time the clustered index key. Data pages(leaf level) of a clustered index are logically ordered by the clustered index key values.
One of the reasons for this design may be the ability to easily merge data from different databases in the distributed database environment. The same idea can be implemented more efficiently using GUID as an alternative key as explained earlier.
More often, the design is inherited from SQL Server’s default behavior when the PK is created and automatically implemented as the clustered index key unless otherwise specified.
Using GUID as clustered index key leads to extensive page and index fragmentation. This is due to its randomness. E.g every time the client app inserts a new Product, a new row must be placed in a specific position i.e specific memory location on a data page. This is to maintain the logical order of the key values. The pages(nodes) are part of a doubly linked list data structure. If there is not enough space on the designated page for the new row, the page must be split into two pages to make the necessary space for the new row. The physical position of the newly allocated page (8KB memory space) in the data file does not follow the order of the index key (it is not physically next to the original page). This is known as logical fragmentation. Splitting data pages introduces yet another type of fragmentation, physical fragmentation which defines the negative effect of the wasted space per page after the split. The increased number of “half full” pages along with the process of splitting the pages has a negative impact on query performance.
The “potential collateral damage” of the decision to use GUID as clustered index key is non-unique non-clustered indexes.
A non-clustered index that is built on a clustered index, at the leaf level, contains row locators- the clustered index key values. These unique values are used as pointers to the clustered index structure and the actual rows – more information can be found here – The data Access Pattern section.
A non-unique NCI can have many duplicate index key values. Each of the key values is “coupled” with a unique pointer – in this case, a GUID value. Since GUID values are random the new rows can be inserted in any position within the range of the duplicated values. This introduces the fragmentation of the NCI. The more duplicated values, the more fragmentation.
The fragmentation can be “postponed” by using the FILLFACTOR setting. The setting instructs SQL Server what percentage of each data page should be used to store data. The “extra” free space per page can “delay” page splits. The FILLFACTOR value isn’t maintained when inserting new data. It is only effective when we create or rebuild an index. So once it’s full, and between the index rebuilds, the data page will be split again during the next insert.
Things are different with the sequential GUID. Sequential GUIDs are generated in ascending order. The “block” of compact, ever-increasing GUIDs is formed on a server and between the OS restarts. Sequential GUIDs created by the Client code on a different server will fall into a separate “block” of guids – see Figure 6. As mentioned before, sequential GUIDs can be created by SQL Server – NEWSEQUENTIALID() fn. initiated by a DEFAULT constraint and/or by the client code. The compact “blocks” of guids will reduce fragmentation.
Conclusion
In SQL Server, GUID is a 16byte binary value stored as UNIQUIEIDENTIFIER data type. NEWID() and NEWSEQUENTIALID() are the two system functions that can be used to create GUIDs in SQL server. The latter is not compliant with the RFC4122 standard. Both GUID types can be created by the client code using functions: UUidCreate(), UuidCreateSequential(). .NET sorts Guid values differently than SQL Server. UNIQUEIDENTIFIER data type re-shuffles first 8 bytes(the first three segments). .NET’s SqlGuid Struct represents a GUID to be stored or retrieved from a DB.
GUID values are often used as primary key/clustered index key values. The randomness of the GUID values introduces logical and physical data fragmentation, which then leads to query performance regression. Sequential GUIDs can reduce fragmentation but still need to be used carefully and with the cost-benefit approach in mind.
Thanks for reading.
Dean Mincic
 Figure 1, ML services
Figure 1, ML services





 Figure 7, Python 3.9 Language extension for SQL Server
Figure 7, Python 3.9 Language extension for SQL Server





 Figure 1, PIVOT Operation
Figure 1, PIVOT Operation



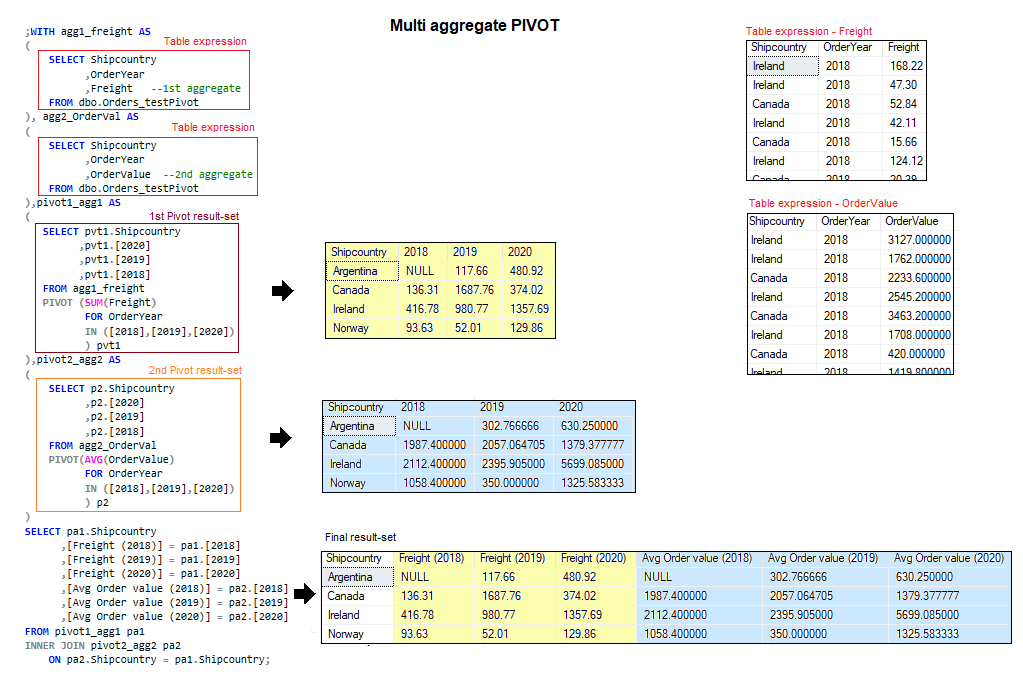 Figure 6, Multi aggregate PIVOT operation
Figure 6, Multi aggregate PIVOT operation Figure 7, Dynamic pivot result
Figure 7, Dynamic pivot result
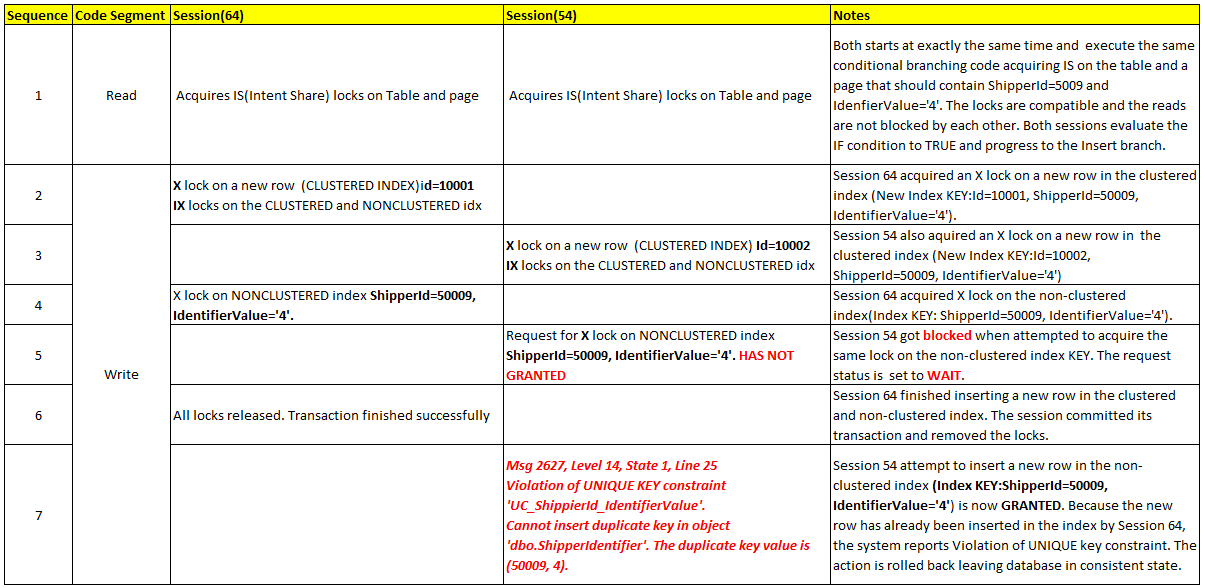
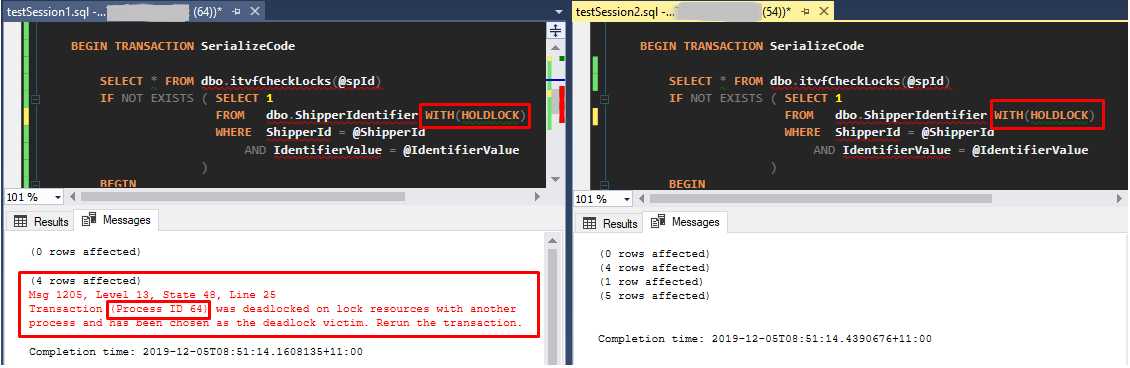
 Figure 4 – the deadlock diagram – serializable isolation level
Figure 4 – the deadlock diagram – serializable isolation level Figure 5, UPDLOCK and HOLDLOCK
Figure 5, UPDLOCK and HOLDLOCK Figure 6, Session 54 – Application locks
Figure 6, Session 54 – Application locks Figure 7, Session 56 – Application locks
Figure 7, Session 56 – Application locks Figure 8, Dummy table pattern
Figure 8, Dummy table pattern Figure 9, Dummy table – blocked session
Figure 9, Dummy table – blocked session




 FIgure 5, cte1 value after 2nd iteration
FIgure 5, cte1 value after 2nd iteration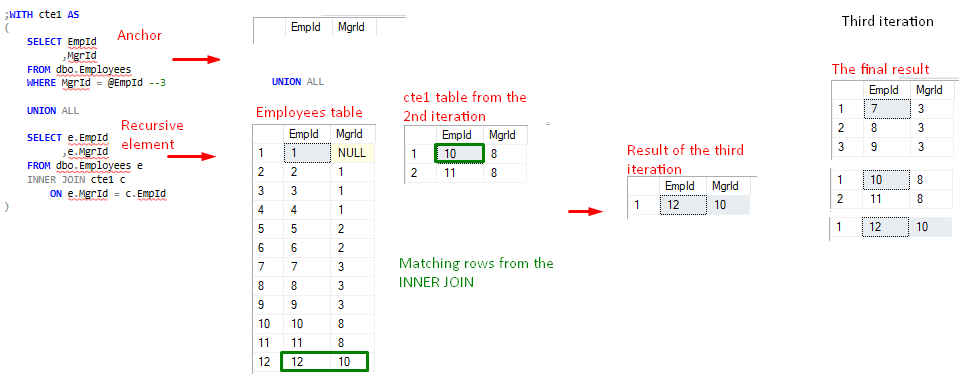

 Figure 8, Detecting existence of circular loops in hierarchies
Figure 8, Detecting existence of circular loops in hierarchies

 Figure 3, the total number of pages per index
Figure 3, the total number of pages per index 
 Figure 3, The tipping point
Figure 3, The tipping point Figure 4, The exact Tipping point number of rows
Figure 4, The exact Tipping point number of rows Figure 5, Query plan change
Figure 5, Query plan change



 Figure 2, Plan stability problem (Parameter sniffing problem)
Figure 2, Plan stability problem (Parameter sniffing problem)








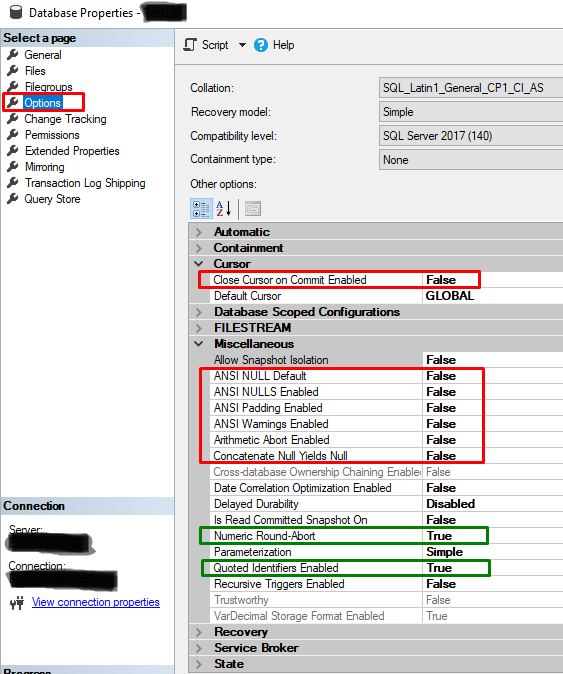



 Figure 9, Post Login events
Figure 9, Post Login events
 Figure 11, Post-login user options values
Figure 11, Post-login user options values FIgure 12, Session level user settings
FIgure 12, Session level user settings  Figure 13, User Option settings sequence
Figure 13, User Option settings sequence