In SQL the logical expressions (predicates) can evaluate TRUE, FALSE and UNKNOWN. The third result is unique to “SQL world“ and is caused by NULL value. This is called Three Valued Logic (3VL). NULL represents the missing or UNKNOWN value.
The logic could be confusing because Boolean, two valued logic expressions can evaluate only to TRUE or FALSE – a comparison between two KNOWN values gives us TRUE or FALSE.
With NULL as a mark or a placeholder, we have an UNKNOWN value, so the question is how to compare a known with an unknown value or an unknown with an unknown.
The logical expressions with NULLs can evaluate to NULL, TRUE and FALSE e.g.
SELECT IIF(1=NULL,'true','unknown') AS [1 = NULL]
,IIF(NULL=NULL,'true','unknown') AS [NULL = NULL]
,IIF(NULL+22<=33,'true','unknown') AS [NULL*22 <= 33]

The result of NULL negations can be confusing too
- The opposite of True is False (NOT True = False)
- The opposite of False is True (NOT False = True)
- The opposite of UNKNOWN is UNKNOWN (NOT NULL = NULL)
Conjunctive(AND) predicates with Nulls evaluates:
- True AND NULL => NULL
- False AND NULL => False
and Disjunctive (OR) predicates with Null evaluates:
- True OR NULL => True
- False OR NULL => NULL
- NULL OR NULL => NULL
The logic is confusing and it was source of an ongoing discussion about NULLS for a long time.
The important thing to note is to put the logic in the context of DB design and to understand how Sql Server treats NULLs in different scenarios. Knowing that we can benefit from using the UNKNOWNS and avoid possible logical errors.
Sql Server is INCONSISTENT when evaluates the logical expressions with NULL values – The same expressions may produce different results TRUE, FALSE and sometimes UNKNOWN.
The following examples shows how SqlServer deals with NULLs in different elements of Tsql language.
QUERY FILTERS (ON,WHERE,HAVING)
Create a couple of test tables:
CREATE TABLE #Products(ProductId INT IDENTITY(1,1)
PRIMARY KEY CLUSTERED
,Name VARCHAR(500) NOT NULL
,Price DECIMAL(8,2) NULL CHECK(Price > 0.00)
,ProductCategoryId INT NULL)
GO
CREATE TABLE #ProductCategories(ProductCategoryId INT
UNIQUE CLUSTERED
,Name VARCHAR(500) NOT NULL)
GO
..and add some data
INSERT INTO #Products(Name,Price, ProductCategoryId)
SELECT tab.*
FROM (VALUES ('Lego',65.99,200)
,('iPad',750.00,300)
,('Gyroscope',NULL,NULL)
,('Beer',3.55,NULL)
,('PC',2500.00,300)) tab(name,price,catid)
GO
INSERT INTO #ProductCategories(ProductCategoryId,Name)
SELECT tab.*
FROM (VALUES (200,'KidsGames')
,(300,'Gadgets')
,(NULL,'Liquor')
,(500,'Camping')) tab(id,name)
GO
Test1: Select all the products over $500.00.
The product with the UNKNOWN(NULL) price will be excluded from the result-set as it was treated as FALSE. Only these rows for which the predicate evaluates to TRUE will be included in the final result-set.
SELECT * FROM #Products WHERE Price > 500

We’ll get the similar result if we try to select all products with not unknown price like:
SELECT * FROM #Products WHERE Price <> NULL;
The result will be an empty set. Not NULL is still UNKNOWN and is treated as FALSE.
The UNKNOWN result is treated as FALSE when evaluated by ON filter.
SELECT p.*,pc.*
FROM #Products p
INNER JOIN #ProductCategories pc
ON p.ProductCategoryId = pc.ProductCategoryId
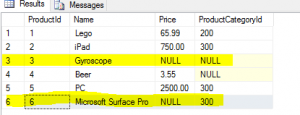
As we can see from the result-set, the product “Gyroscope” is excluded from the result as NULL = NULL evaluated to UNKNOWN and was treated as FALSE.

CHECK Constraint
In case of CHECK constraint, SQL Server treats UNKNOWN result as TRUE.
The product “Gyroscope” has UNKNOWN price. The CHECK constraint on the price column allows only those values which evaluates to TRUE when compared with 0. In this case Sql Server evaluated;
NULL >0 => True
opposed to the previous example when
.. NULL > 500 => False
To confirm the CHECK constraint behavior we can insert a new product into #Products table without getting a Check constraint error:
INSERT INTO #Products(Name,Price, ProductCategoryId)
SELECT 'Microsoft Surface Pro',NULL,300
This can make sense if we put the NULL logic into the context of the DB design, e.g. All products must have price greater than $0 or NULL if the price hasn’t been decided yet.
 UNIQUE Constraint and Set operators
UNIQUE Constraint and Set operators
It was mentioned earlier that NULL = NULL evaluates to UNKNOWN. This means that NULLs are distinct( no two NULLs are equal)
The UNIQUE constraint treats NULL as a distinct value in the context of all other values in the column i.e ProductCategoryId can have only one NULL value and the distinct integers. However, allowing only single NULL value(inserting another NULL value will throw Violation of UNIQUE KEY constraint error), the constraint treats all UNKNOWN values(NULLS) as equal or not distinct.
INSERT INTO #ProductCategories
SELECT NULL, 'Musical Instruments'

The table #ProductCategories has an UNIQUE constraint (enforced by a clustered index) on ProductCategoryId column.
The SET operators UNION, UNION ALL* , EXCEPT, INTERSECT
Sql Server’s Set operators treat NULLs as non distinct, in other words as equal.
e.g. Select the rows from tables @Tab1 and @Tab2 that are common for both tables.
DECLARE @Tab1 TABLE (ID INT, Val VARCHAR(5))
DECLARE @Tab2 TABLE (ID INT, Val VARCHAR(5))
INSERT INTO @Tab1(ID,Val)
SELECT t1.id, t1.Val
FROM (VALUES (1,NULL),(2,NULL),(3,NULL),(4,'Dean'),(5,'Peter'),(6,'Bill')) t1(id,Val)
INSERT INTO @Tab2(ID,Val)
SELECT t2.id, t2.Val
FROM (VALUES (1,NULL),(2,NULL),(3,NULL),(4,'Dean'),(5,'Bahar'),(6,'Nick')) t2(id,Val)
SELECT ID AS keyValue, Val AS Value FROM @Tab1
INTERSECT
SELECT ID,Val FROM @Tab2

As we can see from the result-set, the SET operator treats NULL values as equal e.g Element (1,NULL ) = Element (1,NULL) and therefore belongs to “the red zone”, whereas e.g Element(5,Bahar) <>(5,Peter) and therefore was left out from the result-set.
*UNION ALL is a multi set operator that combines two sets into one non distinct set (takes all elements from both sets)
Aggregate Functions
All Aggregate functions except COUNT(*) ignore NULLs.
DECLARE @Tab3 TABLE (ID INT NULL)
INSERT INTO @Tab3
SELECT t.*
FROM (VALUES(1),(2),(NULL),(NULL),(3) ) t(i)
SELECT AVG(ID) AS [AVG(ID)]
,COUNT(ID) AS [COUNT(ID)]
,SUM(ID) AS [SUM(ID)]
,MAX(ID) AS [MAX(ID)]
,MIN(ID) AS [MIN(ID)]
,'***'AS [***],COUNT(*) AS [COUNT(*)]
from @Tab3

Note: COUNT(col1) eliminate NULLs as the other aggregate functions. However, if we try something like: SELECT COUNT(NULL+1) the function returns 0 eliminating the result of the expression, which is NULL 🙂
Another interesting thing with this, is that SELECT COUNT(NULL) throws an error – Null does not have any data type (COUNT() always does implicit conversion to INT) and e.g. SELECT COUNT(CONVERT(varchar(max),NULL)) returns 0 – now COUNT() has a datatype to work with.
Cursors (Order by)
When a query requests sorting the result-set becomes cursor – sets are not ordered. Sql Server treats NULL values as distinct and sorts the unknowns first if the sort is Ascending (Descending sort order puts NULL values last)
SELECT * FROM #Products ORDER by ProductCategoryId

*Just a small digression. One way to show NULL values last when sorting in Ascending direction is to use tsql’s ability to sort record-set by non-selected columns and/or expressions.
SELECT * ---,[NullsLast]= IIF(ProductCategoryId IS NULL,1,0)
FROM #Products
ORDER BY CASE
WHEN ProductCategoryId IS NULL THEN 1
ELSE 0
END
,ProductCategoryId
The NULL expressions results can explain the “unexpected” results when used in anti-semi joins, but that will be covered in a separate post.
Conclusion
Three valued logic is unique to DB wold. ANSI SQL Standard provides rules/guidelines about NULL values. However, different RDBMS may handle NULLs differently in different situations. It is important to understand how Sql Server treats NULL values in different elements of tsql language. Using NULLs in the context of DB design can make 3VL work for you.
Thanks for reading.
Dean Mincic
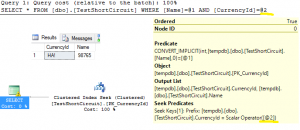
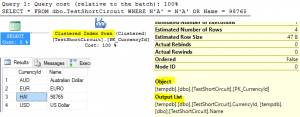 Figure 2: Disjunctive predicates, query simplification and SC
Figure 2: Disjunctive predicates, query simplification and SC