Mutex in Sql Server
Summary
RDBMS systems are multi-user systems which serve many clients at the same time. Being able to process large amounts of requests is very important up to the point that we often trade data consistency to improve concurrency. However, there are situations when access to a particular segment of code needs to be serialized. This is similar to the Critical section in concurrent programming when concurrent access to shared resources can lead to unexpected behavior. To protect the code e.g. in c# we use lock/monitor, mutex, or semaphore, and in Sql Server we use dummy lock tables, isolation levels/lock hints or application locks. This post presents four different ways of protecting the critical code in SQL Server.
What is Mutex?
Mutex stands for mutually exclusive. It is a construct used to serialize access to the shared resources. Mutex is a locking mechanism that prevents race conditions allowing access to the protected code (critical section) to only one process/thread at a time.
Thread safe code – c# example
The next example shows a simple use of the mutex class to serialize access to a “critical section”.
The c# console application code can be found here.
The program performs the division of two random numbers. The operation that follows sets operands, num1, and num2 values to 0. This is done 5 times in a For loop.
for (int i = 0; i < 5; i++)
{
num1 = rndNum.Next(1, 5); //min value 1, max value 5
num2 = rndNum.Next(1, 5);
result = (num1 / num2);
num2 = 0;
num1 = 0;
}
The critical section is executed concurrently by multiple threads* causing a DivideByZeroException exception. Thread1(t1) and Thread2(t2) started executing the code at almost the same time. (t1) has performed the division and assigned value 0 to the num2 variable. At the same time, (t2) was in the middle of the division when (t1) set the divisor(num2) value to 0. The new condition caused Division by zero exception.
*Note: The runtime environment starts execution of the program with the Main () method in one thread and then creates three more threads using System.Threading.Thread class.
To avoid this situation we need to serialize access to the code above. One way to do that is to use the Mutex class to provide exclusive access to the critical section. (un-comment mutex objects in the code)
...
public static Mutex m = new Mutex();
m.WaitOne(); //thread waits until its safe to enter
for (int i = 0; i < 5; i++)
{
num1 = rndNum.Next(1, 5); //min value 1, max value 5
num2 = rndNum.Next(1, 5);
result = (num1 / num2);
num2 = 0;
num1 = 0;
}
//releases ownership of the mutex and unblocks other threads that are
//trying to gain ownership of the mutex
m.ReleaseMutex();
Now, treads (t1) and (t2) execute the code one at a time without causing the exception.
The code is now “thread safe”. 🙂
Mutex in SQL Server
There are several ways to serialize access to a critical section in SQL Server. Although some approaches are more proper than others, it’s good to understand them all because, sometimes a specific situation can limit our options.
Set up test environment
The code used in the experiments can be downloaded by following the links below.
- Test table – The main test table is used to simulate the effects of the concurrent inserts. (download here)
- Dummy table – table used to present one of the mutex implementation techniques. (download here)
- ITVF – an inline function used to track table locks requested by the concurrent connections.
(download here)
There are many scenarios that can be used to demonstrate the effects of concurrent query execution on the critical section i.e Lost updates, double inserts etc. In this post I’ll focus on the concurrent inserts only.
The base query for the following experiments. (also available here)
WAITFOR TIME '14:13:40';
SET XACT_ABORT ON;
DECLARE @spId VARCHAR(1000) = '54,64';
DECLARE @ShipperId INTEGER
,@IdentifierValue VARCHAR(250);
SET @ShipperId = 50009;
SET @IdentifierValue = 4; -- add a new IdentifierValue
BEGIN TRANSACTION SerializeCode
SELECT * FROM dbo.itvfCheckLocks(@spId) --get metadata
IF NOT EXISTS (
SELECT 1
FROM dbo.ShipperIdentifier
WHERE ShipperId = @ShipperId
AND IdentifierValue = @IdentifierValue
)
BEGIN
SELECT * FROM dbo.itvfCheckLocks(@spId) --get metadata
WAITFOR DELAY '00:00:00.10'; --wait 10ms
INSERT INTO dbo.ShipperIdentifier (
ShipperId
,IdentifierValue)
VALUES (@ShipperId, @IdentifierValue)
SELECT * FROM dbo.itvfCheckLocks(@spId) --get metadata
END
COMMIT TRANSACTION;
Essentially, the query logic encapsulates a read-and-write query with the latter being executed if the first returns an empty set.
In this scenario, more than one connection is trying to insert a unique combination of ShipperId and IdentifierValue into the table. Only one “unique” insert is allowed and that is enforced by the Unique constraint on the two columns.
I’ll be executing the query from the context of the two different SSMS sessions. To simulate concurrent code execution, before each experiment, we define the exact time when the code will run i.e. WAITFOR TIME ’14:13:40′. We also need to capture the two SIDs (session IDs) for which we want to collect metadata i.e. DECLARE @spId VARCHAR(1000) = ‘54,64’;
Insert race condition
An insert race condition is a situation where multiple instances of the same code execute a conditional insert at the same time. The condition for the insert can evaluate to true for all concurrent calls causing multiple inserts of the same values. This can lead to logical errors – duplicate rows or violation of Unique constraint/Primary key etc.
So, lets execute the base query code as is and demonstrate the Insert race condition.

Figure 1, Constraint violation caused by the insert race condition
Table hints and isolation levels
The first* method to serialize access to a critical section is to use combinations of table hints and/or isolation levels. This will permit only one code execution at a time.
*NOTE: The only reason why I put this method as the first solution is because, for me personally, it was the most interesting approach to research. However, in production environment, depending on the situation, I would probably first try to implement Application locks explained in the following section.
Previous, unsuccessful attempt to insert a new row follows the sequence presented in Figure 2 below. The list is compiled using dbo.itvfCheckLocks outputs.
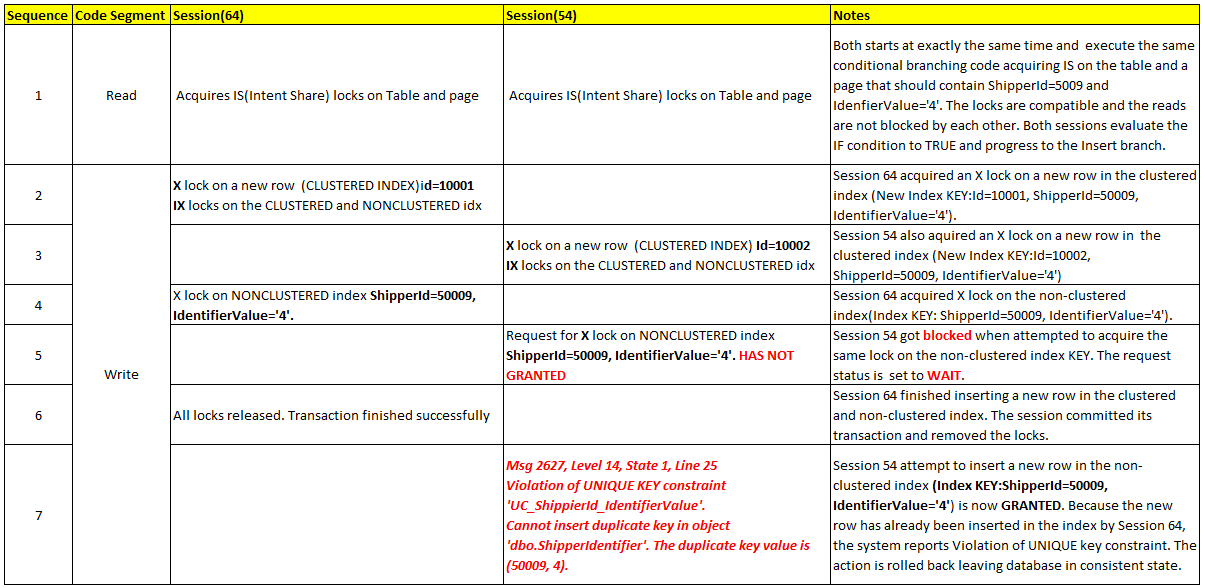
Figure 2, Locking pattern – key violation error
One of the first things that comes to mind is to elevate the transaction isolation level.
If we used REPEATABLE READ tran. isolation level the outcome will be exactly the same. The isolation level would keep S locks, if acquired during the first-read query, until the end of the transaction. That way repeatable read prevents the inconsistent analysis aka repeatable read anomaly. However, in this case, there won’t be any S locks acquired and held because the requested row (ShipperId=50009, IdentifierValue=4) does not exist.
The next isolation level is SERIALIZABLE. For this test, I’ll use the (HOLDLOCK) table hint. The hint acts as a SERIALIZABLE transaction isolation level, only the scope of the isolation is reduced to a table level. However, as opposed to i.e NOLOCK, HOLDLOCK “holds” its locks (sticks to its guns 🙂 ) until the end of the transaction.
The complete code can be found here.
... SELECT 1 FROM dbo.ShipperIdentifier WITH(HOLDLOCK) WHERE ShipperId = @ShipperId ...
“Reset” dbo.ShipperIdentifier table, run the test query again, and observe the results.
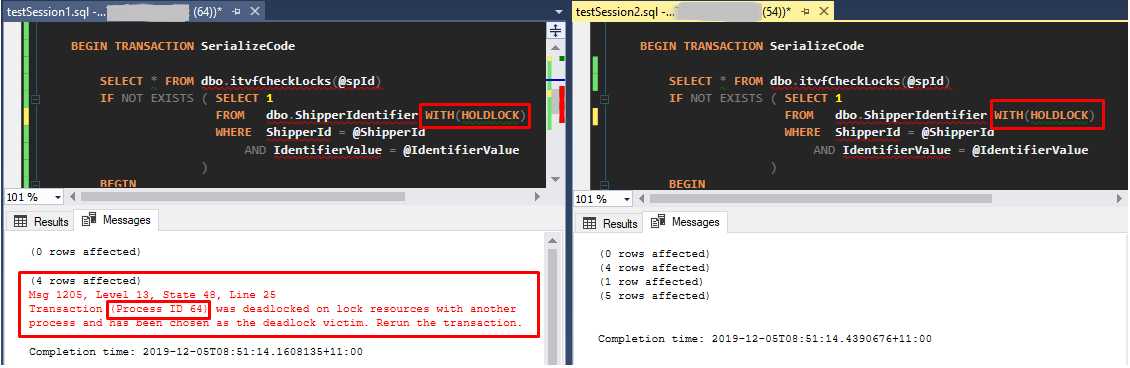
Figure 3, Deadlock situation and SERIALIZABLE isolation level
This time Session 54 successfully completed the insert and Session 64 was chosen to be a deadlock victim. Figure 4 shows the deadlock diagram.
 Figure 4 – the deadlock diagram – serializable isolation level
Figure 4 – the deadlock diagram – serializable isolation level
NOTE: I’ve used MS Profiler to get the graphical plan. Use the Deadlock graph, Lock:Deadlock and Lock:Deadlock events. Once you get the event, right-click on the Deadlock graph row/ Extract event data to save the diagram for further analysis
If we correlate information from Figure 4 and dbo.itvfCheckLocks we can conclude the following;
Similar to the situation presented in Figure 2, both sessions used NCI to access the requested information. During the read phase, both sessions acquired IS locks on an index page where IdentifierValue = 4 (and the subsequent, IdentifierValue=5) is supposed to be. The sessions have also acquired RangeS-S locks on the NCI key range, IdentifierValue=5. The locks are compatible and both sessions evaluated conditional expression to TRUE.
During the “write “phase – INSERT query, both sessions have acquired X locks on the two new rows to be inserted in the Clustered index -Session(64) on a new Id=10001 and Session(54) on Id=10002.
Now, in order to acquire an X lock on the new row(s) to be inserted in the NCI, the existing RangeS-S locks must be first converted to RangeI-N locks. This is the point where the deadlock happens – see Figure 4. Because RangeI-N and RangeS-S are not compatible, Sessions 64 and 54 wait on each other to release their RangeS-S locks. After a certain period of time, in this case, the SQL Server engine decided to “kill” session(64) and let (54) successfully finish.
The idea is to acquire non-compatible locks during the read phase and to keep the locks until the end of the transaction – see lock compatibility matrix. We can use the UPDLOCK table hint to force the lock manager to use U locks instead of S locks, in our case RangeS-U instead of RangeS-S.
Change the test query code and reset the test environment. Find the new code here.
... SELECT 1 FROM dbo.ShipperIdentifier WITH(UPDLOCK,HOLDLOCK) WHERE ShipperId = @ShipperId ...
 Figure 5, UPDLOCK and HOLDLOCK
Figure 5, UPDLOCK and HOLDLOCK
If we run the concurrent code again, we’ll see that one of the sessions acquired RangeS-U lock on the non-clustered index Key (ShipperId=50009, ShipperIdentifier = 5, and Id =3). Both sessions have acquired IU locks on the NCI page which “hosts” the above key(UI locks are compatible). Other Session now must WAIT until the first Session releases the RangeS-U locks before it enters the conditional branching and performs the read query.
The first session releases the RangeS-U lock at the end of the transaction. At this point, the new row (ShipperIdentifier = 4) has already been inserted in the table (NCI and CI ). The blocked session now can continue and acquire its own RangeS-U and IU locks. This time the read query can find the requested row. The conditional expression evaluates to FALSE and skips the INSERT query.
We managed to serialize access to the critical code by acquiring non-compatible locks at the beginning of the process and holding the locks until the end of the code segment.
Application locks
Another way to prevent concurrent access to a critical section in sequel is to use Application locks. This “special” type of lock is designed to serialize access to a critical section purely from the code perspective – very much like mutex in c# demonstrated earlier.
Application locks are a mechanism that allows an application to acquire an app-lock on a critical section within a transaction or a connection(session). The locks do not affect tables/pages/rows but purely the code they encompass.
The available application lock types are: S(Shared) IS(Intent Share), U(Update), X(Exclusive), and IX(Intent Exclusive). The rules follow the standard compatibility matrix. More on the application locks can be found here.
Application locks are implemented through system-stored procedures:
- sys.sp_getapplock – used to acquire locks
- @Resource: Specifies the case-sensitive name of the application lock.
- @LockMode: specifies the lock type S, IS, U, X, IX
- @LockOwner: specifies the scope of the lock -Transaction or
Session - @LockTimeout: specifies the timeout in milliseconds. Stored proc. will return an error if it cannot acquire the lock in this interval
- @DbPrincipal: specifies security context. The caller must be a member of one of the following security objects
-
- database_principal
- dbo – special database user-principal
- db_owner – fixed db role
- (DEFAULT – Public db role)
-
- sys.spreleaseapplock. – used to release locks
- @Resource:
- @LockOwner: specifies the scope of the lock -Transaction or
- @DbPrincipal
In the next example, we use a new test query that implements application locks. Reset the test environment and concurrently execute two instances of the new test query.
My concurrent sessions were 54 and 56. Even if executed at the same time, Session 54 has acquired an app lock first making the second session(Sid=56) wait until 54 releases the app lock resource. The allowed wait time(@LockTImeout) is set to 1.5s.
Below is the output of the query execution.
 Figure 6, Session 54 – Application locks
Figure 6, Session 54 – Application locks Figure 7, Session 56 – Application locks
Figure 7, Session 56 – Application locks
As we can see, the application lock has serialized access to the critical section within an explicit transaction. Application lock did not affect the “standard” data locking routine defined by the transaction’s isolation level and the query itself. The lock used a non-compatible mode (@LockMode = ‘Exclusive’) which prevented concurrent access.
If we used one of the compatible lock modes – ‘Shared‘, ‘IntentShared‘, or ‘IntentExclusive‘, the test would fail causing a Violation of UNIQUE KEY constraint UC_ShippierId_IdentifierValue … similar to one presented in Figure1.
My personal opinion is that this is the cleanest way to serialize access to a critical section.
The next two methods are more workarounds than proper solutions.
Dummy lock tables
This method includes a dummy table, a table that is not part of the database schema(at least not logically). Its sole purpose is to be exclusively locked by one of the concurrent sessions allowing only one session to access the subsequent code/queries at a time.
To execute the test, reset the test table and use the dummy table SQL script from here.
...
BEGIN TRANSACTION SerializeCode
SELECT LockMe = COUNT(*) FROM dbo.DummyLock WITH(TABLOCKX); --exclusive table lock
...
In my experiment, I had two sessions, Sid=66 and, Sid=65. The former had exclusively locked the dummy table before Sid=65 requested the lock. This pattern ensured that only one session could execute the protected code at a time.
Similar to Application locks, the dummy table routine does not restrict access to the objects (tables, views.. etc.) within a critical section, through different access paths. i.e. Session(88) attempts to update a row in dbo.ShipperIdentifier table during the above action. The concurrent update will follow standard Transaction isolation level rules regardless of the status of the dummy table.
 Figure 8, Dummy table pattern
Figure 8, Dummy table pattern
 Figure 9, Dummy table – blocked session
Figure 9, Dummy table – blocked session
Tables and Loops
The last method encapsulates a critical section in an infinite loop. A conditional branching within the loop checks for the existence of a dummy table (or a global aka double hash, temporary table). If the table does not exist, the current session will be able to access the “protected code” and subsequently drop the table and exit the loop. However, if the table already exists, the concurrent session(s) will keep looping, constantly checking if the table still exists. Once the table gets dropped by the current session(the only session that can access the DROP TABLE code), a concurrent session will be able to create a table and access the critical section.
As mentioned before, this method is more of a workaround than a proper solution and can introduce a number of performance issues i.e. excessive drop/create table actions, increased CPU workload, etc.
....
WHILE(1 = 1)
BEGIN
IF OBJECT_ID('dbo.LockCodeSection','U') IS NULL
BEGIN
BEGIN TRY
CREATE TABLE dbo.LockCodeSection(LockMe BIT)
BEGIN TRANSACTION SerializeCode
....
The complete script can be found here. Reset the test environment and run the script in two separate SSMS sessions and at the same time.

Figure 10, Tables and Loops 🙂
From the output, we can see that Session Sid=66 was the first one to create the dummy table and to access the critical section. At the same time, Session Sid=65 was constantly trying to enter the code segment by checking the existence of the dummy table. It made 8486 attempts in order to access the critical section. Finally, it accessed the code in a serial manner without causing any constraint violation..
Conclusion
Sometimes access to particular segments of code needs to be serialized between concurrent client connections. A protected segment of code is also known as a critical section. In concurrent programming, we use objects/constructs like mutex, semaphore, or locks in order to serialize threads’ access to the shared resources making them thread-safe. In SQL programming critical sections/queries are of the declarative type usually describing what we want to achieve but not how. Therefore, serializing SQL code i.e. one or more queries encapsulated in an explicit transaction, comes down to ensuring that only one session/connection can access the same code through the same object i.e. the same stored procedure at the same time. However, the same protected code can be concurrently accessed by other sessions through different objects i.e. views, other stored procs, dynamic queries, etc.
SQL Server’s application locks closely resemble mutexes in application programming. Implemented through a couple of system-stored procedures, application locks are easy to understand and implement. There are many different ways to achieve the same goal e.g. by controlling the types of locks (UPDLOCK) and/or mimicking behavior of the ANSI transnational isolation levels applied only to specific table(s) (SERIALIZABLE aka HOLDLOCK) within a critical section. Other solutions may seem like workarounds implementing more imperative approaches such as Tables and Loops.
Thanks for reading.
Dean Mincic