Data providers and User Options
Summary
Some time ago I decided to write a quick post about ANSI_WARNINGS, one of Sql Server’s user options. Half way through, I discovered many interesting things around the mechanisms that sets Client connection/session user settings. That was definitely more fun to research and blog about 🙂
Sql Server configuration settings include several settings called User options. Those options, along with some other settings define the user connections environment related to query processing. The options define i.e how queries handle the 3VL(Three Valued Logic – ANSI_NULLS) or how they enforce atomicity of the explicit transactions (XACT_ABORT) etc.
There are a few levels where the options can be set: Server, Database and session levels. The values can also be independently set by Sql Server engine and the data providers after the successfully established Client connection. Different Db tools like SSMS may have their own settings on top of the previously mentioned. This blog aims to shed some light on the processes that change the connection/session user option settings.
SQL Server Configuration Settings overview
Sql Server’s configuration settings can be set on three different levels.
- Server configuration settings
- Database configuration settings
2.1 Connection settings set by Sql Server/ Data providers during the Database Login process/after the successfully established Client connection.
- SQL Server session(connection) configuration settings (SET statements on a session level)
For the most of the settings, the values can be set on more than one level. The overlap introduces the precedence of the values set on the lower levels over those set on the higher levels i.e QUOTED_IDENTIFIER setting value defined on the session level (3) overrides the same setting value on the database(2) and/or Server level(1).
Sometimes, the concept may be confusing and this is only my personal feel, since there is a number of different ways to assign values to the same settings and on a few different levels.
Some of the settings can only be set on certain levels. i.e Max workers treads (configures the number of worker threads that are available to SQL Server processes) can be set only on the server(instance) level, and AUTO_CREATE_STATISTICS( If not already available, Query Optimizer creates statistics on individual columns used in a predicate) can only be set on database level*.
NOTE: All database settings are inherited from the model db during the database creation.
As mentioned, this post will be focusing only on a sub-set of the server settings, the User Options settings.
User Options
Figure 1 below shows the categories of the user options and their values. The bit settings are presented as decimal numbers – this will be explained later in the blog.

User Options can be set up on three different levels; Server, Database and Session level.
Server level
Server level defines User Option settings for all Client connections. User options on this level can be managed in a few different ways.
-
sys.sp_configure , system stored procedure
EXEC sys.sp_configure
@configname = 'user_options'
![]()
Figure 2, Default User Option(s)
The system stored procedure manages server configuration settings.
@configname is an option name or, in our case the name of a group of options. config_value is a combination of values presented in Figure 1. The default config_value is 0 representing the default state of user settings – all set to OFF.
More about config_value
The config_value is a small, positive integer. This means that the maximum value that can be used is 32768 – 1 = 32767 or 215 – 1. One bit is used for the integer sign.
The config_value is also a 2 bytes(16 bits) bitmap used to store the user setting values. The first 15bits are used to store the values (although the 1st – DISABLE_DEF_CNST_CHK has been discontinued since Sql Server 2012).
Lets say we want to turn ON the following user settings
– ANSI_WARNINGS (decimal value 8)
– ARITHABORT (decimal value 64) and
– CONCAT_NULL_YIELDS_NULL (decimal value 4096)
Figure 3 is a graphical representation of the 2byte bitmap and the corresponding binary and decimal values. The last bit (binary 215 ,decimal 32768) is not in use.
 Figure 3, User Options – config_value
Figure 3, User Options – config_value
To turn ON the corresponding bits, we just add decimal values like : 8 + 64 +4096 = 4168 (or using bitwise OR) i.e SELECT (8 | 64 | 4096) We then pass the value to the configvalue parameter of the sys.sp_configure system stored procedure.
EXEC sys.sp_configure @configname = 'user_options'
,@configvalue = 4168
RECONFIGURE;
This means that the all subsequent client connections may have the settings turned ON. More on this in the following sections.
-
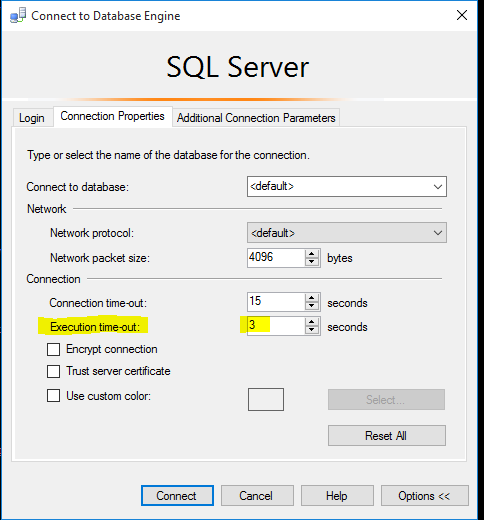
SSMS GUI, Server Settings/Properties/Connections
Another way to manage User Options on the server level is by using SSMS tool. Figure 4 shows the user_options accessed through the UI.

The default state of the user option values on the Server level is all OFF.
Database level
Similar to the Server level user options, database level user options define the user option values for all the Clients that will be connecting to the particular database. The database settings are supposed to override the same settings that were set on a higher, server level.
Database level user options as well as server level user options are, by default all set to OFF.
NOTE: The Database level user options becomes more interesting in the context of Contained Sql server(2012+) databases or its Cloud counterpart , the Azure SQL Database
To change user options on the database level use ALTER DATABASE statement.
ALTER DATABASE TestDB
SET QUOTED_IDENTIFIER ON
,NUMERIC_ROUNDABORT ON
GO
To check the current user option values we can use system functions or system views.
SELECT DATABASEPROPERTYEX('TestDB','IsNumericRoundAbortEnabled')
--OR
SELECT [name]
,is_ansi_warnings_on
,is_ansi_padding_on
,is_ansi_nulls_on
,is_ansi_null_default_on
,is_arithabort_on
,is_numeric_roundabort_on
,is_quoted_identifier_on
,is_cursor_close_on_commit_on
,is_concat_null_yields_null_on
FROM sys.databases
WHERE [name] = N'TestDB'
Figure 5 shows a sub-set of the User Options available on the database level.
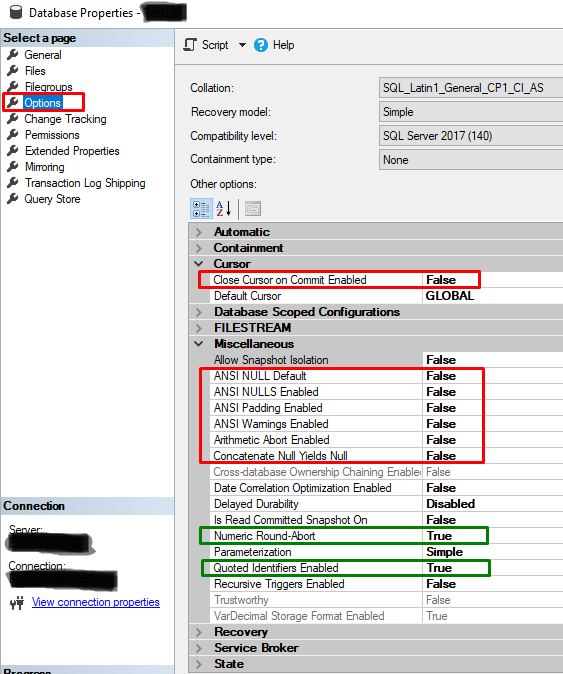
Figure 5, Database level user options
The following user options are available on the server level but not on the database level.
– ARITHIGNORE
– NOCOUNT
– XACT_ABORT
– IMPLICIT_TRANSACTIONS
ANSI NULL Default (ANSI_NULL_DEFAULT) represents the Server level ANSI_NULL_DFLT_ON and ANSI_NULL_DFLT_OFF.
By default, server level user option settings should be overwritten by the corresponding database level settings. However, for most of the options this is not true. Data providers responsible for establishing connections between client applications and database will override the settings defined on both levels.
Connection settings set by Sql Server/ Data provider
I was not able to find many white papers that covers Sql Server Data providers’ role in configuring user options. The following conclusions are based on my personal research and experiments.
For a start, let’s set up a simple Ext. Event session that reports on the following events;
- Login event. The main Event field of interest will be the option_text field.
- sql_batch_starting and sql_batch_completed – sql_text field
- sql_statement_starting and sql_statement_completed – sql_text field
The last two events will be used in the subsequent experiments.

Now, let’s connect to a test database using a simple powershell script and observe the Login event attributes
## Create a simple connection to Sql Server using .NET Framework Data Provider for Sql Server
$sqlConn = New-Object System.Data.SqlClient.SqlConnection;
$sqlConn.ConnectionString = @('Data Source=tcp:(local);' `
+'Initial Catalog=TestDB;' `
+'Integrated Security=True;' `
+'Pooling=False;' `
+'Application Name=TestDataProviderConnSettings;');
## Open and Close the connection.
$sqlConn.Open(); ##This is where we capture the Login event
$sqlConn.Close();
$sqlConn.Dispose();

Figure 7, options_text field value
By analysing the output we can observe a couple of interesting things.
- The Server/Database user settings have been overwritten by the new values i.e ANSI_PADDING is originally set to OFF on both levels and then turned ON during the SqlConnection.Open() process.
- Some other connection settings are set i.e dateformat, transaction isolation level ..etc
In addition, I compared the user option values set by different data providers;
- .NET Framework Data Provider for Sql Server/ODBC/OLEDB (pshell script)
- ODBC v3 and v7 (Python and sqlCmd)
- Microsoft JDBC Driver 7.0 for SQL Server (java app)
The results were always exactly the same – the identical set of user option values.
Now, the question I was trying to answer was ; What was the process that set the values presented in the Figure 7? The option_text event field description says:
“Occurs when a successful connection is made to the Server. This event is fired for new connection or when connections are reused from a connection pool”
This may suggest that Data Providers may be responsible for setting the option values and at some stage during the login process.
To further investigate this, I have ran a powershell script similar to the one used in the previous test. This time I used ODBC Data Source Administrator (for 32bit env) to trace the ODBC communication(function calls) between the Client app and Sql Server.
## Create a simple connection to Sql Server using .NET Framework Data Provider for ODBC
$sqlConn = New-Object System.Data.Odbc.OdbcConnection;
$sqlConn.ConnectionString = @('Driver={SQL Server Native Client 11.0};' `
+'Server=tcp:(local);' `
+'Database=TestDB;' `
+'Trusted_Connection=yes;');
##Note: Connection pooling is disabled for all ODBC connections
## see odbcad32.exe (or odbcad64.exe) Connection Pooling Tab
## Open and Close the connection
$sqlConn.Open();
$sqlConn.Close();
$sqlConn.Dispose();

Figure 8, ODBC Administrator – Trace ODBC function calls
The trace did not show any ODBC function calls that set up the user options captured by the Login event. It was “nice and clean” log.
In the next experiment, I used a simple sqlcmd.exe script to connect to the same database. Sqlcmd utility uses (at least ver. 14.0.1 I have on my laptop) ODBC Driver 13 for Sql Server. This is visible in the ODBC trace file – Figure 10.
C:\Users>sqlcmd -S tcp:(local) -d TestDB
Again, no “interesting” function calls during the login phase. However, there were two function (SQLSetStmtAttrW) calls that took place after the successfully established connection.
 Figure 9, Post Login events
Figure 9, Post Login events Figure 10, ODBC Trace snapshot – SQLSetStmtAttrW() function
Figure 10, ODBC Trace snapshot – SQLSetStmtAttrW() function
The log shows that there were two sets of changes on the user options initiated by data providers;
1. Pre-login/During the login process (captured by the Login event)
2. Post-login changes (captured by sql_batch/sql_statement events)
Post-login changes
In this experiment I’ve tried to consolidate and document the post login user options values set by different providers. The idea is to execute a simple program using different data providers, that will:
- connect to the test database
- execute a view that selects the user option values for the current session.
- output the results of the view
i. e C:\Users>sqlcmd -S tcp:(local) -d TestDB -q “select * from dbo.vwGetSessionSETOptions”
The view definition:
CREATE OR ALTER VIEW [dbo].[vwGetSessionSETOptions]
AS
SELECT TAB.OptionName
,Setting = IIF(TAB.Setting = 0,'OFF','ON')
FROM (VALUES ('DISABLE_DEF_CNST_CHK' ,(1 & @@OPTIONS)) --not in use
,('ANSI_WARNINGS' ,(8 & @@OPTIONS)) --iso settings statements
,('ANSI_PADDING' ,(16 & @@OPTIONS))
,('ANSI_NULLS' ,(32 & @@OPTIONS))
,('ANSI_NULL_DFLT_ON' ,(1024 & @@OPTIONS))
,('ANSI_NULL_DFLT_OFF' ,(2048 & @@OPTIONS))
,('ARITHABORT' ,(64 & @@OPTIONS)) --query execution statements
,('ARITHIGNORE' ,(128 & @@OPTIONS))
,('NUMERIC_ROUNDABORT' ,(8192 & @@OPTIONS))
,('NOCOUNT' ,(512 & @@OPTIONS))
,('QUOTED_IDENTIFIER' ,(256 & @@OPTIONS)) --miscellaneous statements
,('CURSOR_CLOSE_ON_COMMIT' ,(4 & @@OPTIONS))
,('CONCAT_NULL_YIELDS_NULL' ,(4096 & @@OPTIONS))
,('XACT_ABORT' ,(16384 & @@OPTIONS)) --transaction statements
,('IMPLICIT_TRANSACTIONS' ,(2 & @@OPTIONS))
) TAB(OptionName,Setting)
UNION ALL
SELECT '-------','-------'
UNION ALL
SELECT 'PROGRAM_NAME: ' +[program_name] + '** CLIENT_INTERFACE_NAME : '+client_interface_name
,'CLIENT_VERSION: ' +CAST(client_version as varchar(3))
FROM sys.dm_exec_sessions
WHERE session_id = @@SPID
GO
The output shows the user options that would be applied on any batch/stored proc, function, ad-hoc query if executed within the active connection (or the @@spid session from SQL Server’s perspective). The partitioned view includes the data provider’s details available through sys.dm_exec_sessions dynamic management view.
 Figure 11, Post-login user options values
Figure 11, Post-login user options values
From the result (the figure above may be an overkill 🙂 ) we can conclude that data providers can change some of the user settings and that can produce unexpected results. Consider the scenarios below;
- If we execute a Python script that i.e inserts a some rows into a table..
import pyodbc;
#import pytds
conn = pyodbc.connect('Driver={SQL Server};'
'Server=tcp:localhost;'
'Database=TestDB;'
'Trusted_Connection=yes;'
'Poolig = false')
cursor = conn.cursor()
cursor.execute('INSERT INTO dbo.testImplicitTran(Id) SELECT 511')
.. the INSERT will NOT happen since the data provider had set the IMPLICIT_TRANSACTIONS to ON. To see how SQL Server implements the post-login change, run the script along with the Extended Event Session – Figure 9.
- If we execute an sqlCmd query to i.e insert some values in a table that has a filtered index, we’ll get the following error.
C:\Users>sqlcmd -S tcp:(local) -d TestDB -q "INSERT INTO dbo.testQIdentifierOFF SELECT 555"
Msg 1934, Level 16, State 1, Server ENETT-NB290, Line 1 INSERT failed because the following SET options have incorrect settings: ‘QUOTED_IDENTIFIER’. Verify that SET options are correct for use with indexed views and/or indexes on computed columns and/or filtered indexes and/or query notifications and/or XML data type methods and/or spatial index operations.
Other data providers may change settings like; dbLib data provider sets ANSI_WARNINGS user option value to OFF. This may cause the logical errors that may be difficult to debug.
SSMS post login changes
SSMS application performs its own set of post-login changes. The changes can be managed through the application UI on two levels;
- Current session level(query editor) – The changes affects only the current session.
- Right Click on the query editor area/ Query Options/Execution – ANSI
- Application level where the changes affects all sessions.
- Tools/Options/Query Execution/ SQL Server/ANSI
Developers, should be aware of the fact that the same query executed from SSMS and a Client application may behave differently and produce different results. i.e The INSERT query executed through the Python script above would commit changes if executed in SSMS.
Pre-login changes
As mentioned before – Figure 7, there are nine User settings set by Data providers (or Sql Server engine) during the login process. In the next experiment I’ll try to show how the nine Server level settings get affected/overridden by the pre-login changes – loosely speaking 🙂
Initially, all server level user settings are turned OFF – Figure 2 and that includes the 9 options mentioned before.
Let’s see what happens on the session level if we set ALL Server level user options to ON. For the experiment I’ll use a PowerShell script similar to the one used before, to connect to Sql Server.
## Create a simple connection to Sql Server using .NET Framework Data Provider for Sql Server
$sqlConn = New-Object System.Data.SqlClient.SqlConnection;
$sqlConn.ConnectionString = @('Data Source=tcp:(local);' `
+'Initial Catalog=TestDB;' `
+'Integrated Security=True;' `
+'Pooling=False;' `
+'Application Name=TestDataProviders;');
## Open and Close the connection
$sqlConn.Open();
###$sqlCmd = New-Object System.Data.OleDb.OleDbCommand;
$sqlCmd = $sqlConn.CreateCommand()
$sqlCmd.CommandText = "SELECT * FROM dbo.vwGetSessionSETOptions";
$result = $sqlCmd.ExecuteReader();
$table=New-Object System.Data.DataTable;
$table.Load($result);
$format = @{Expression={$_.OptionName};Label=”Option Name”;width=90},@{Expression={$_.Setting};Label=”Setting”; width=50}
$table | Format-Table $format;
$sqlConn.Close();
$sqlConn.Dispose();
Before executing the script, lets change server level user settings and check the effects of the changes through SSMS GUI, Figure 4.
DECLARE @user_settingsBitMask SMALLINT;
SET @user_settingsBitMask = ( POWER(2,15)- 1 ) -- all 15 settings turned on
- 1024 --turn off ANSI_NULL_DFLT_ON
- 64 --turn off ARITHABORT
EXEC sys.sp_configure
@configname = 'user_options'
,@configvalue = @user_settingsBitMask; --31679
GO
RECONFIGURE;
NOTE: Some of the user settings are mutually exclusive.
- ANSI_NULL_DFLT_ON and ANSI_NULL_DFLT_OFF
- ARITHABORT and ARITHIGNORE
The figure below shows the session level user options settings output for the two Server level user options settings scenarios. The snapshot combines two outputs.
 FIgure 12, Session level user settings
FIgure 12, Session level user settings
As we can see, the user options business is pretty unclear and confusing. Combining findings from the previous experiments, I compiled a table that may explain the sequence in which the user options are set, but before that, just another thing to mention – the ANSI_DEFAULTS setting. The setting controls(sets to ON) a group of user options values. This is to provide the ANSI standard behavior for the options below;
- ANSI NULLS
- ANSI_PADDING
- ANSI_WARNINGS
- QUOTED_IDENTIFIER
- ANSI_NULL_DFLT_ON
- CURSOR_CLOSE_ON_COMMIT
- IMPLICIT_TRANSACTIONS
The status of the ANSI_DEFAULTS can be checked using the query below.
SELECT ansi_defaults FROM sys.dm_exec_sessions WHERE session_id = @@SPID
When checked, status is usually 0 (not set) because some of the user settings from the list gets overridden by the pre-login/post login processes mentioned before.
 Figure 13, User Option settings sequence
Figure 13, User Option settings sequence
During application login attempt, data provider/Sql server engine turns ON a set of user options grouped in the ANSI_DEFAULT settings. This overrides the user options set on server level(Phase 1). Right after the change, another set of changes overrides a couple of ANSI_DEFAULTS options and a few server level user options(Phase 2). At this stage the login process is finished and 9 out of 15 option values is reported by the login xEvent(option_text field).The color of user options at the final session level shows the levels from which the values came from.
*The ARITHABORT and ARITHIGNORE shows a different behavior.
- The options are mutually exclusive if set on server level (only one setting can be set to ON.
- If one of the settings is set on server level the setting will not be changed through the login process.
- If none of the settings is set on server level, ARITHABORT will be set to ON during the Phase 2.
- Only ARITHABORT value will be reported by the login_xevent.
Data providers like ODBC, dbLib perform additional changes to the user options after successfully establishing a database connection.
Session level setting
Once connected, Client code can override previously set user options by using SET statements directly in the code. This would be the final override of the user option values 🙂 . The scope of the settings will be the current session( or from the Client’s perspective, the current connection). The following coder shows a few user options set in a stored procedure’s header…
CREATE OR ALTER PROCEDURE dbo.uspSetUserOptions AS BEGIN SET ANSI_DEFAULTS ON; SET IMPLICIT_TRANSACTIONS OFF; SET ARITHABORT ON; SET QUOTED_IDENTIFIER ON; SET NOCOUNT ON; SET XACT_ABORT ON; -- code .... RETURN; END
Conclusion
The User Options are a set of configurable elements that affect query behavior i.e handling 3VL(three valued logic), division by zero situations, data truncation rules etc. As Sql developers we need to be aware of the environment in which our queries are being executed. There are many different levels where user options can be set; Server, Database and session levels. Session level has precedence over the other two levels. However, Sql server can set up its own default user option values during and after the login phase – when a client application makes an attempt to connect to Sql Server. Data providers can also independently change user option settings, during and after the login process. The impact of the changes can introduce logical errors such as e.g always rolled back inserts/updates/deletes ( implicit transaction set to on) or code execution errors such as insert failures on a table with a filtered index. There are scenarios when user options settings can cause the sneaky logical errors that are very difficult to debug e.g. what if NULL = NULL suddenly evaluates to true(ansi nulls off).
The session level can provide a place where we can set user option values which will override all previously set options. Designing templates for Sql Server objects (stored procedures, functions..etc) that will include the option settings in the header may be a good way to put the whole user option confusion to the rest 🙂
Thanks for reading.
Dean Mincic


 Figure 4, MS Profiler – tsql batch execution events
Figure 4, MS Profiler – tsql batch execution events  Figure 5, MS Profiler – parameterised batch RPC event
Figure 5, MS Profiler – parameterised batch RPC event
 Figure 7, parameterised batch request – cached plan
Figure 7, parameterised batch request – cached plan
 Figure 9, RPC request and nested stored procedures
Figure 9, RPC request and nested stored procedures Figure 10, Showplan XML Statistic Profile event class
Figure 10, Showplan XML Statistic Profile event class