One of the common tasks in the DB community is moving databases from one SQL server instance to another.
For simple environments, it could be just a matter of backing up the database on one server/instance and restoring it on another.
Sometimes, even if we successfully restore the database on a new server, create all necessary logins and change the application connection string to point to the new instance we still get the Database not accessible or Login failed error messages.
The common reason for the errors is the disconnection between the DB users and their logins – The orphaned DB users.
The technique we usually use to re-connect the users is to call a system-stored procedure that will do the Login-DbUser remapping.
-- Re-connects an orphaned db user "db_user1" with login "user1"
EXEC sp_change_users_login
@Action='update_one'
,@UserNamePattern='db_user1'
,@LoginName=user1;
GO
Why does the problem occur in the first place and what we can do to prevent it. The following is a little bit of theory and a couple of examples that will illustrate the problem.
In SQL Server, there are eleven different database user types. The type I am focusing on today is Db User based on the SQL Server authenticated Login. The complete list can be found here.
Every principal (an entity that can request SQL Server resources) has two main properties:
- Principal ID or ID
- Security ID or SID
The scope of influence of a principal depends on the level that the principal operates on e.g SQL Server Level principals operate on an SQL Server Instance level while the Database level principals operate on a database level.
- Logins are principals whose scope is SQL Server instance
- DB Users are principals whose scope is Database
DB Users – based on SQL Server Logins
When we create an SQL Server Login, SQL Server assigns ID and SID to the created principal.
- ID – (INT) -Uniquely identifies Login as an SQL Server securable (resource managed by SQL Server). The ID is generated by SQL Server
-
SID – (VARBINARY(85)) – Uniquely identifies the security context of the Login. The security context depends on how the identifier was created. The Login SIDs can be created by :
- Windows User/Group. The SID will be unique across the User/group domain and will be created by the domain.
- SQL Server. The SID is unique within SQL Server and created by SQL Server – used in the example below.
- Certificate or asymmetric key. (cryptography in SQL Server will be covered in one of the following posts)
The information about the Logins is stored in the master database
The following code will create a few SQL objects to illustrate the problem.
-- Create a couple of test databases
USE master
GO
CREATE DATABASE TestOrphanedUsersDB_1
GO
CREATE DATABASE TestOrphanedUsersDB_2
GO
--Create Sql Server Logins
CREATE LOGIN Login1
WITH PASSWORD='abc'
,CHECK_POLICY = OFF
GO
CREATE LOGIN User2 --the login name is User2 :)
WITH PASSWORD ='abc'
,CHECK_POLICY = OFF
GO
The logins are stored in the master database and can be viewed using sys.server_principals system view:
SELECT name AS [Login Name]
,principal_id AS ID
,[sid] AS [SID]
,[type_desc] AS [Login Type]
FROM master.sys.server_principals
WHERE name IN ('Login1','User2')
Query Results (the identifiers may be different on different PCs)
Now we need to create a few database users.
As mentioned before, there are eleven different types of database users. For this exercise, we’ll create DB users based on SQL server logins.
--Create database users for the Sql Logins.
--The User SIDs will match the Login SIDs
USE TestOrphanedUsersDB_1
GO
CREATE USER User1
FOR LOGIN Login1 --User1(SID) = Login1(SID)
GO
CREATE USER User2
FOR LOGIN User2
GO
USE TestOrphanedUsersDB_2
GO
CREATE USER User1-- The user names are unique on a database level
FOR LOGIN Login1
SQL Server has assigned the Principal IDs and Security IDs to the newly created users.
- ID – (INT) -Uniquely identifies DB users as a database securable.
- SID – (VARBINARY(85)) – Uniquely identifies the security context of the User. The security context depends on how the identifier was created – In the example the DB Users security context depends on the Logins and therefore the User SIDs will match the Login SIDs.
The information about the database users is stored on the database level and can be viewed using the sys.database_principals system view.
USE TestOrphanedUsersDB_1
GO
SELECT name AS [DbUser Name]
,principal_id AS [Principal ID]
,[sid] AS [SID]
,[type_desc] AS [Db User Type]
FROM sys.database_principals
WHERE name IN ('User1','User2')

..and for the second database…
USE TestOrphanedUsersDB_2
GO
SELECT name AS [DbUser Name]
,principal_id AS [Principal ID]
,[sid] AS [SID]
,[type_desc] AS [Db User Type]
FROM sys.database_principals
WHERE name IN ('User1','User2')

The diagram below shows the relationship between Logins and Users.

Image 1, Logins/Users mapping
Case Scenario:
An application uses two databases, TestOrphanedUsers_1 and TestOrphanedUsers_2. We decided to move the application’s backend to a new instance by backing up and restoring the two on the new server.
The restored databases contain all of the previously defined DB users since the principals are a part of the databases. The original server logins were not transferred because they belong to the original master database.
At this stage, the logins are not mapped to the users and the application is not able to access the backend.
To simulate the scenario, we’ll remove the previously created logins.
USE master GO DROP LOGIN Login1 GO DROP LOGIN User2 GO
If we removed the logins using SSMS UI, we would get a message

The users left in the databases are now called “Orphaned Users”. The users without the corresponding logins cannot be used to access the databases. This situation mimics the database restore on a new SQL Server instance.
The next step is to create new logins. At this stage, we can do two things.
- Create new logins (as we did before). SQL server’s engine will assign new SIDs to the logins. These identifiers will not match the existing user SIDs and consequently, we’ll have to remap the Logins to the Users (to make SIDs match). To make a match, the process will replace the old user SIDs with the new Login ones.
--Create Sql Server Logins
USE master
GO
CREATE LOGIN Login1
WITH PASSWORD='abc'
,CHECK_POLICY = OFF
GO
CREATE LOGIN User2
WITH PASSWORD ='abc'
,CHECK_POLICY = OFF
GO
Using the principals’ metadata we can see the mismatch between SIDs .
Login SIDs:
To restore the previous mapping (see Image 1) we need to remap the orphaned users as:
.. using the sys.sp_change_users_login system stored procedure.
--list all orphaned users
EXEC TestOrphanedUsersDB_1.sys.sp_change_users_login
@Action ='report'
GO
EXEC TestOrphanedUsersDB_2.sys.sp_change_users_login
@Action ='report'
-- remap
EXEC TestOrphanedUsersDB_1.sys.sp_change_users_login
@Action='update_one'
,@UserNamePattern='User1'
,@LoginName=Login1
GO
EXEC TestOrphanedUsersDB_1.sys.sp_change_users_login
@Action='update_one'
,@UserNamePattern='User2'
,@LoginName=User2
GO
This will replace the user SIDs with the new Login SIDs
The stored procedure supports the Auto_Fix action type that can be used in a specific scenario in which we create a missing login with the same name as the orphaned user the login was created for.
More information about the procedure can be found here.
NOTE: SQL Server 2016 is the last database engine version to support the sys.sp_change_users_login procedure.
Microsoft recommends using ALTER USER instead.
--remap User1(TestOrphanedUsersDB_2) to login Login1 USE TestOrphanedUsersDB_2 GO ALTER USER User1 WITH LOGIN=Login1 GO
- Create logins implicitly specifying SIDs to match the DB. user SIDs,
USE master
GO
--Create Sql Server Logins
CREATE LOGIN Login1
WITH PASSWORD='abc'
,CHECK_POLICY = OFF
--copied from TestOrphanedUsersDB_1.User1 or TestOrphanedUsersDB_2/User1
,SID =0X043C965331B69D46B3D6A813C9238090
GO
USE master
GO
CREATE LOGIN User2 --the login name is User2 :)
WITH PASSWORD ='abc'
,CHECK_POLICY = OFF
--copied from TestOrphanedUsersDB_1.User2
,SID=0XC871212ABD68D04998E89480285DDE70
GO
Now we can test the mapping using the Logins to access the databases.
Conclusion:
The database users created for(or based on) SQL Server authenticated logins must have a valid link to the logins. The link is the Security identification(SID) varbinary.
Due to different scopes of the principals, DB Users, when restored on a different server, may become disconnected(orphaned) from the corresponding Logins(the new logins may have new SIDs that don’t match the original DB User SIDs). In this situation, the applications are not able to connect to the database.
To remap the principals we can use two approaches; system sp sys.sp_change_users_login to change the DB user SIDs to match the new Login SIDs or to create new Logins using the original user SIDs.
It’s worth mentioning that the latter may cause the “Supplied parameter sid is in use” error if the specified SID is already in use by an existing Login.
Thanks for reading.
Dean Mincic



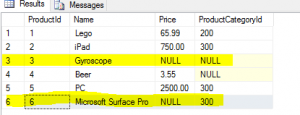 UNIQUE Constraint and Set operators
UNIQUE Constraint and Set operators



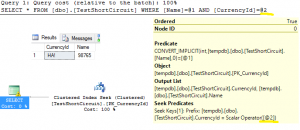
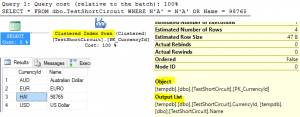 Figure 2: Disjunctive predicates, query simplification and SC
Figure 2: Disjunctive predicates, query simplification and SC