Recursive Common Table Expressions , table expressions and more…
Summary
Common Table Expressions were introduced in SQL Server 2005. They represent one of several types of table expressions available in Sql Server. A recursive CTE is a type of CTE that references itself. It is usually used to resolve hierarchies.
In this post I will try to explain how CTE recursion works, where it sits within the group of table expressions available in Sql Server and a few case scenarios where the recursion shines.
Table Expressions
A table expression is a named query expression that represents a relational table. Sql Server supports four types of table expressions;
- Derived tables
- Views
- ITVF (Inline Table Valued Functions aka parameterised views)
- CTE (Common Table Expressions)
- Recursive CTE
In general, table expressions are not materialised on the disk. They are virtual tables present only in RAM memory (they may be spilled to disk as a result of i.e memory pressure, size of a virtual table etc..). The visibility of the table expressions may vary i.e views and ITVF are db objects visible on a database level, whereas they scope is always on an SQL statement level – table expressions cannot operate across different sql statements within a batch.
Benefits of table expressions are not related to query execution performances but to the logical aspect of the code !
Derived Tables
Derived tables are table expressions also known as sub-queries. The expressions are defined in the FROM clause of an outer query. The scope of derived tables is always the outer query.
The following code represents a derived table called AUSCust.
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N'Australia'
) AS AUSCust;
--AUSCust is a derived table
The derived table AUSCust is visible only to the outer query and the scope is limited to the sql statement.
Views
Views (sometimes referred to as virtual relations) are reusable table expressions. A view definition is stored as an Sql Server object along with objects such as; user defined tables, triggers, functions, stored procedures etc.
The main advantage of Views over other types of table expressions is their re-usability i.e derived queries and CTE have scope limited to a single statement.
Views are not materialised, meaning that the rows produced by views are not stored permanently on disk. Indexed views is Sql Server(similar but not the same as the materialised views in other db platforms) are special type of views that can have their result-set permanently stored on disk – more on indexed views can be found here.
Just a few basic guidelines on how to define SQL Views.
-
SELECT * in the context of a View definition behaves differently then when used as a query element in a batch.
CREATE VIEW dbo.vwTest AS SELECT * FROM dbo.T1 ...
The view definition will include all columns from the underlying table, dbo.T1 at the time of the view creation. This means that if we change the table schema (i.e add and/or remove columns) the changes will not be visible to the view – the view definition will not automatically change to support the table changes. This can cause errors in the situations when i.e a view try to select non-existing columns from an underlying table.
To fix the problem, we can one of the two system procedures: sys.sp_refreshview or sys.sp_refreshsqlmodule.
To prevent this behavior follow the best practice and explicitly name the columns in the definition of the view. - Views are table expressions and therefore cannot be ordered. Views are not cursors! It is possible, though, to “abuse” the TOP/ORDER BY construct in the view definition in attempt to force sorted output. e.g .
CREATE VIEW dbo.MyCursorView AS SELECT TOP(100 PERCENT) * FROM dbo.SomeTable ORDER BY column1 DESC
Query optimiser will discard the TOP/ORDER BY since the result of a table expression is always a table – selecting TOP(100 PERCENT) doesn’t make any sense anyway. The idea behind Table structures is derived from a concept in Relational database theory known as Relation.
-
During processing a query that references a view, the query from the view definition gets unfolded or Expanded and implemented in the context of the main query. The consolidated code(query) will then be optimised and executed.
ITVF (Inline Table Valued Functions)
ITVFs are are reusable table expressions that support input parameters. The functions can be treated as parameterised views.
CTE (Common Table Expressions)
Common table expressions are similar to derived tables but with several important advantages;
A CTE is defined using a WITH statement, followed by a table expression definition. To avoid the ambiguity (TSQL uses WITH keyword for other purposes i.e WITH ENCRYPTION etc) the statement preceding CTE’s WITH clause MUST be terminated with a semi-column. This is not necessary if the WITH clause is the very first statement in a batch i.e in a VIEW/ITVF definition)
NOTE: Semi-column, the statement terminator is supported by ANSI standard and it is highly recommended to be used as a part of TSQL programming practice.
Recursive CTE
SQL Server supports recursive querying capabilities implemented trough Recursive CTEs since version 2005(Yukon).
Elements of a recursive CTE
- Anchor member(s) – Query definitions that;
- returns a valid relational result table
- is executed ONLY ONCE at the beginning of query execution
- is positioned always before the first recursive member definition
- the last anchor member must be followed by UNION ALL operator. The operator combines the last anchor member with the first recursive member
- UNION ALL multi-set operator. The operator operates on
- Recursive member(s) – Query definitions that;
- returns a valid relational result table
- have reference to the CTE name. The reference to the CTE name logically represents the previous result set in a sequence of executions. i.e The first “previous” result set in a sequence is the result the anchor member returned.
- CTE Invocation – Final statement that invokes recursion
- Fail-safe mechanism – MAXRECURSION option prevents database system from the infinite loops. This is an optional element.
Termination check
CTE’s recursive member has no explicit recursion termination check.
In many programming languages, we can design method that calls itself – a recursive method. Every recursive method needs to be terminated when a certain conditions are satisfied. This is Explicit recursion termination. After this point the method begins to return values. Without termination point recursion can end up calling itself “endlessly”.
CTE’s recursive member termination check is implicit , meaning that the recursion stops when no rows are returned from the previous CTE execution.
Here is a classic example of a recursion in imperative programming. The code below calculates the factorial of an integer using a recursive function(method) call.
...
static void Main(string[] args)
{
int Number = 0;
long Result;
...
//function call
Result = CalculateFactorial(Number);
...
}
public static long CalculateFactorial(int number)
{
//Termination check (factorial of 0 is 1
if (number == 0)
return 1;
//Recursive call
return number * CalculateFactorial(number - 1);
}
Complete console program code can be found here.
MAXRECURSION
As mentioned above, recursive CTEs as well as any recursive operation may cause infinite loops if not designed correctly. This situation can have negative impact on database performance. Sql Server engine has a fail-safe mechanism that does not allow infinite executions.
By default, the number of times recursive member can be invoked is limited to 100 (this does not count the once-off anchor execution). The code will fail upon 101st execution of the recursive member.
Msg 530, Level 16, State 1, Line xxx
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The number of recursions is manged by MAXRECURSION n query option. The option can override the default number of maximum allowed recursions. Parameter (n) represents the recursion level. 0<=n <=32767
Important note:: MAXRECURSION 0 – disables the recursion limit!
Figure 1 shows an example of a recursive CTE with its elements

Figure 1, Recursive CTE elements
Declarative recursion is quite different than traditional, imperative recursion. Apart of the different code structure, we can observe the difference between the explicit and the implicit termination check. In the CalculateFactorial example, the explicit termination point is clearly defined by the condition: if (number == 0) then return 1.
In the case of recursive CTE above, the termination point is implicitly defined by the INNER JOIN operation, more specifically by the result of the logical expression in its ON clause: ON e.MgrId = c.EmpId. The result of the table operation drives the number of recursions. This will become more clear in the following sections.
Use recursive CTE to resolve Employee hierarchy
There are many scenarios when we can use recursive CTEs i.e to separate elements etc. The most common scenario I have come across during many years of sequeling has been to use recursive CTE to resolve various hierarchical problems.
The Employee tree hierarchy is a classic example of a hierarchical problem that can be solved using Recursive CTEs.
Example
Let’s say we have an organisation with 12 employees. The following business rules applies;
- An employee must have unique id, EmpId
- enforced by: Primary Key constraint on EmpId column
- An employee can be be managed by 0 or 1 manager.
- enforced by: PK on EmpId, FK on MgrId and NULLable MgrId column
- A manager can manage one or more employees.
- enforced by: Foreign Key constraint(self referenced) on MgrId column
- A manager cannot manage himself.
- enforced by: CHECK constraint on MgrId column
The tree hierarchy is implemented in a table called dbo.Employees. The scripts can be found here.

Lets present the way recursive CTE operate by answering the question: Who are the direct and indirect subordinates of the manager with EmpId = 3?
From the hierarchy tree in Figure 2 we can clearly see that Manager (EmpId = 3) directly manages employees; EmpId=7, EmpId=8 and EmpId=9 and indirectly manages; EmpId=10, EmpId=11 and EmpId=12.
Figure 3 shows the EmpId=3 hierarchy and the expected result. The code can be found here.

Figure 3, EmpId=3 direct and indirect subordinates
So, how did we get the final result.
The recursive part in the current iteration always references its previous result from the previous iteration. The result is a table expression(or virtual table) called cte1(the table on the right side of the INNER JOIN). As we can see, cte1 contains the anchor part as well. In the very first run(the first iteration), recursive part cannot reference its previous result because there was no previous iteration. This is why in the first iteration only the anchor part executes and only once during the whole process. The anchor query result-set gives recursive part its previous result in the second iteration. The anchor acts as a flywheel if you will 🙂
The final result builds up through iterations i.e Anchor result + iteration 1 result + iteration 2 result …
The logical execution sequence
The test query is executed by following the logical sequence below:
- The SELECT statement outside the cte1 expression invokes the recursion. The anchor query executes and returns a virtual table called cte1. The recursive part returns an empty table since it has no its previous result. Remember, the expressions in set based approach are evaluated all at once.
 Figure 4, cte1 value after 1st iteration
Figure 4, cte1 value after 1st iteration - The second iteration begins.This is the first recursion. The anchor part played its part in the first iteration and from now on returns only empty sets. However, the recursive part can now reference it’s previous result(cte1 value after the first iteration) in the INNER JOIN operator. The table operation produces the result of the second iteration as shown in the figure below.
 FIgure 5, cte1 value after 2nd iteration
FIgure 5, cte1 value after 2nd iteration - Second iteration produces a non-empty set, so the process continues with the third iteration – the second recursion. Recursive element now references the cte1 result from the second iteration.
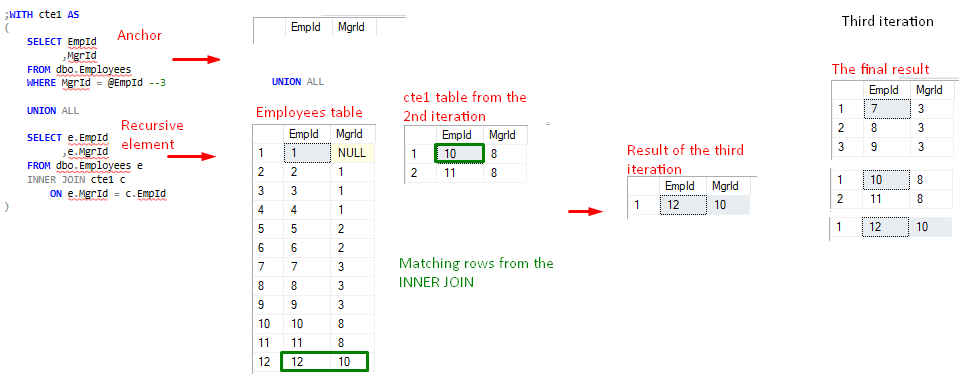
FIgure 6, cte1 value after 3rd iteration - An interesting thing happens in the 4th iteration – the third recursion attempt. Following the previous pattern, the recursive element uses the cte1 result from the previous iteration. However, this time there are no rows returned as a result of the INNER JOIN operation, and the recursive element returns an empty set. This is the implicit termination point mentioned before. In this case, INNER JOIN’s logical expression evaluation dictates the number of recursions.
Because the last cte1 result is an empty result-set, the 4th iteration(or 3rd recursion) is “canceled” and the process is successfully finished.

Figure 7, The final iteration
The logical cancellation of the 3rd recursion (the last recursion that produced an empty result-set does not count) will become more clear in the following, recursive CTE execution plan analysis section.We can add OPTION(MAXRECURSION 2) query option at the end of the query which will limit the number of allowed recursions to 2. The query will produce the correct result proving that only two recursions are required for this task.Note: From the physical execution perspective, the result-set is progressively(as rows bubble up) sent to the network buffers and back to the client application.
Finally, the answer on the question above is :
There are six employees who directly or indirectly report to the Emp = 3. Three employees, EmpId= 7, EmpId=8 and EmpId=9 are direct subordinates and EmpId=10, EmpId=11 and EmpId=12 are indirect subordinates.
Knowing the mechanics of recursive CTE, we can easily solve the following problems.
- find all the employees who are hierarchically above the EmpId = 10 (code here)
- find EmpId=8 ‘s direct and the second level subordinates(code here)
In the second example we control depth of the hierarchy by restricting the number of recursions.
Anchor element gives us the first level of hierarchy, in this case, the direct subordinates. Each recursion then moves one hierarchy level down from the first level. In the example, the starting point is EmpId=8 and his/hers direct subordinates. The first recursion moves one more level down the hierarchy where EmpId=8 ‘s second level subordinates “live”.
Circular reference problem
One of the interesting things with hierarchies is that the members of a hierarchy can form a closed loop where the last element in the hierarchy references the first element. The closed loop is also known as circular reference.
In the cases like this, the implicit termination point, like the INNER JOIN operation explained earlier, will simply not work because it will always return a non-empty result-set for the next recursion to go on. The recursion part will keep rolling until it hits Sql Server’s fail-safe, the MAXRECURSION query option.
To demonstrate circular reference situation using previously set up test environment, we’ll need to
- Remove Primary and Foreign key constraints from dbo.Employees table to allow the closed loops scenarios.
- Create a circular reference (EmpId=10 will manage his indirect manager , EmpId = 3)
- Extend the test query used in the previous examples, to be able to analyse hierarchy of the elements in the closed loop.
The extended test query can be found here.
Before continuing with the circular ref. example, lets see how the extended test query works. Comment out the WHERE clause predicates(the last two lines) and run the query against the original dbo.Employee table
...
)
SELECT cte1.EmpId
,cte1.MgrId
,recLvl
,pth
,isCircRef
FROM cte1
--WHERE cte1.isCircRef = 1 --returns only circular ref. hierarchies
-- AND cte1.recLvl <= 2; --limits final result to two recursions
 Figure 8, Detecting existence of circular loops in hierarchies
Figure 8, Detecting existence of circular loops in hierarchies
The result of the extended query is exactly the same as the result presented in the previous experiment in Figure 3. The output is extended to include the following columns
- pth – Graphically represents the current hierarchy. Initially, within the anchor part, it simply adds the first subordinate to MgrId=3, the manager we’re starting from. Now, each recursive element takes the previous pth value and adds the next subordinate to it.
- recLvl – represents current level of recursion. Anchor execution is counted as recLvl=0
- isCircRef – detects existence of a circular reference in the current hierarchy(row). As a part of recursive element, it searches for the existence of an EmpId that was previously included in the pth string.
i.e if the previous pth looks like 3->8->10 and the current recursion adds ” ->3 “, (3->8 >10 -> 3) meaning that EmpId=3 is not only an indirect superior to EmpId=10, but is also EmpId=10’s subordinate – I am boss or your boss, and you are my boss kind of situation 😐
Lets now make necessary changes on dbo.Employees to see the extended test query in action.
Remove PK and FK constraints to allow circular references and add a “bad boy circular ref” to the table.
ALTER TABLE dbo.Employees
DROP CONSTRAINT FK_MgrId_EmpId
,CONSTRAINT PK_EmpId;
GO
--insert circ ref.
INSERT INTO dbo.Employees (EmpId,MgrId)
VALUES (3,10) -- EmpId 10 is managing EmpId 3
GO
Run the extended test query, and analyse the results (don’t forget to un-commet previously commented WHERE clause at the end of the script)
The script will execute 100 recursions before gets interrupted by the default MAXRECURSION. The final result will be restricted to two recursions .. AND cte1.recLvl <= 2; which is required to resolve EmpId=3’s hierarchy.
Figure 9 shows a closed loop hierarchy, maximum allowed number of recursions exhausted error and the output that shows the closed loop.

Figure 10, Circular reference detected
A few notes about the circular reference script.
The script is just an idea of how to find closed loops in hierarchies. It reports only the fist occurrence of a circular reference – try to remove WHERE clause and observe the result.
In my opinion, the script (or a similar versions of the script) can be used in production environment for i.e troubleshooting purposes or as a prevention from creating circular references in an existing hierarchy. However, it needs to be secured by appropriate MAXRECURSION n, where n is expected depth of the hierarchy.
This script is non-relational and relies on a traversal technique. It is always the best approach to use declarative constraints (PK, FK, CHECK..) to prevent any closed loops in data.
Execution plan analysis
This segment explains how Sql Server’s query optimiser(QO) implements a recursive CTE. There is a common pattern that QO uses when constructing the execution plan. Run the original test query and include the actual execution plan
Like the test query, the execution plan has two branches: the anchor branch and the recursive branch. Concatenation operator, which implements the UNION ALL operator, connects results from the two parts forming the query result.
Let’s try to reconcile the logical execution sequence mentioned before and the actual implementation of the process.
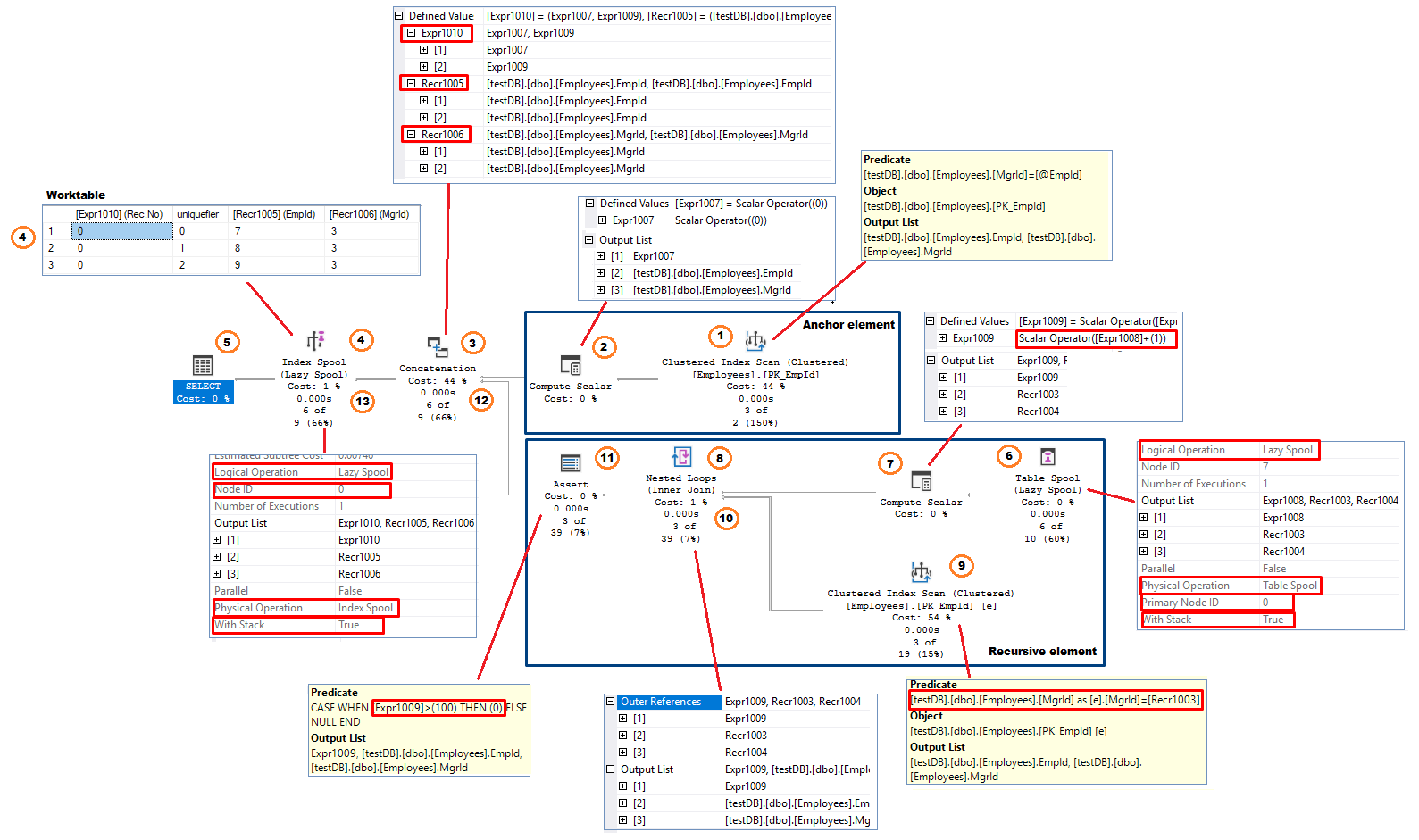
Figure 11, Recursive CTE execution plan
Following the data flow (right to left direction) the process looks like:
Anchor element (executed only once)
- Clustered Index Scan operator – system performs index scan. In this example, it applies expression MgrId = @EmpId as a residual predicate. Selected rows(columns EmpId and MgrId) are passed (row by row) back to the previous operator.
- Compute Scalar The operator adds a column to the output. In this example, the added column’s name is [Expr1007]. This represents the Number of Recursions. The column has initial value of 0; [Expr1007]=0
- Concatenation – combines inputs from the two branches. In the first iteration, the operator receives rows only from the anchor branch. It also changes the names of the output columns. In this example the new column names are:
- [Expr1010] = [Expr1007] or [Expr1009]* *[Expr1009] holds number of recursions assigned in the recursive branch. It does not have value in the first iteration.
- [Recr1005] = EmpId(from the anchor part) or EmpId(from the recursive part)
- [Recr1006] = MgrId(from the anchor part) or MgrId (from the recursive part)
- Index Spool (Lazy Spool) This operator stores the result received from the Concatenation operator in a worktable. It has property “Logical Operation” set to “Lazy Spool”. This means that the operator returns its input rows immediately and does not accumulate all rows until it gets the final result set (Eager Spool) . The worktable is structured as a clustered index with the key column [Expr1010] – the recursion number. Because the index key is not unique, the system adds an internal, 4 byte uniquifier to the index key to ensure that all rows in the index are, from the physical implementation perspective, uniquely identifiable. The operator also has property “With Stack” set to “True” which makes this version of the spool operator a Stack Spool A Stack Spool operator always has two components – an Index Spool that builds the index structure and a Table Spool that acts as a consumer of the rows stored in the worktable that was built by the Index Spool.
At this stage, the Index Spool operator returns rows to the SELECT operator and stores the same rows in the worktable. - SELECT operator returns EmpId and MgrId ([Recr1005] , [Recr1006]). It excludes [Expr1010] from the result. The rows are sent to the network buffer as they arrive from the operators downstream
After exhausting all rows from the Index Scan operator, the Concatenation operator switches context to the recursive branch. The anchor branch will not be executed again during the process.
Recursive element
- Table Spool (Lazy Spool). The operator has no inputs and, as mentioned in (4) acts as a consumer of the rows produced by the Index Spool and stored in a clustered worktable. It has property “Primary Node” set to 0 which points to the Index Spool Node Id. It highlights the dependency of the two operators. The operator
- removes rows it read in the previous recursion. This is the first recursion and there are no previously read rows to be deleted. The worktable contains three rows (Figure 4).
- Read rows sorted by the index key + uniquifier in descending order. In this example, the first row read is EmpId=9, MgrId=3.
Finally, the operator renames the output column names. [Recr1003] =[Recr1005], [Recr1004] =[Recr1006] and [Expr1010] becomes [Expr1008].
NOTE: The table spool operator may be observed as the cte1 expression on the right side of the INNER JOIN (figure 4) - Compute Scalar The operator adds 1 to the current number of recursions previously stored in column [Expr1007].The result is stored in a new column, [Expr1009]. [Expr1009] = [Expr1007] + 1 = 0 + 1 = 1. The operator outputs three columns, the two from the table spool ([Recr1003] and [Recr1004]) and [Expr1009]
- Nested Loop(I) operator receives rows from its outer input, which is the Compute Scalar from the previous step, and then use [Recr1003] – represents EmpId from the Table Spool operator, as a residual predicate in the Index Scan operator positioned in the Loop’s inner input. The inner input executes once for each row from the outer input.
- Index Scan operator returns all qualified rows from dbo.Employees table (two columns; EmpId and MgrId) to the nested loop operator.
- Nested Loop(II): The operator combines [Exp1009] from the outer input and EmpId and MgrId from the inner input and passes the three column rows to the next operator.
- Assert operator is used to check for conditions that require query to be aborted with an error message. In the case of recursive CTEs , assert operator implements “MAXRECURSION n” query option. It checks whether the recursive part reached the allowed (n) number of recursions or not. If the current number of recursions, [Exp1009](see step 7) is greater than (n), the operator returns 0 causing a run time error. In this example, Sql Server uses its default MAXRECURSION value of 100. The expression looks like: CASE WHEN [Expr1009]> 100 THEN 0 ELSE NULL If we decide to exclude the failsafe by adding MAXRECURSION 0, the assert operator will not be included in the plan.
- Concatenation combines inputs from the two branches. This time it receives input from the recursive part only and outputs columns/rows as shown in the step 3.
- Index Spool (Lazy Spool) adds the output from concatenation operator to the worktable and then passes it to the SELECT operator. At this point the worktable contains the total of 4 rows: three rows from the anchor execution and one from the first recursion. Following the clustered index structure of the worktable, the new row is stored at the end of the worktable
-
The process now resumes from step 6. The table spool operator removes previously read rows (the first three rows) from the worktable and reads the last inserted row, the fourth row.
Conclusion
CTE(Common table expressions) is a type of table expressions available in Sql Server. A CTE is an independent table expression that can be named and referenced once or more in the main query.
One of the most important uses of CTEs is to write recursive queries. Recursive CTEs always follow the same structure – anchor query, UNION ALL multi-set operator, recursive member and the statement that invokes recursion. Recursive CTE is declarative recursion and as such has different properties than its imperative counterpart e.g declarative recursion termination check is of implicit nature – the recursion process stops when there are no rows returned in the previous cte.
Thanks for reading.
Dean Mincic